git: usare git bisect per un baco impossibile
Durante la risoluzione di un baco relativo ad una applicazione iphone mi sono ritrovato con un problema molto strano: una UITableView contenuta all'interno di una UIView con una UINavigationBar; sulla barra di navigazione è presente un tasto per impostare le celle in modalità di editing (in particolare è possibile cancellare le celle). Quando le celle sono in modalità di editing esse presentano un tasto rosso circolare sulla sinistra, almeno è quello che doveva e avveniva precedentemente: ora in modalità di editing non si presenta il tasto circolare a sinistra ma un tasto normale a destra quando si scorre il dito verso destra sulla cella in questione.
Questo baco è stato segnalato e io non me ne ero mai accorto, e qualche tempo prima il tutto funzionava correttamente; la prima cosa da fare è stata controllare che tra una versione funzionante e l'attuale non ci fossero delle modifiche nel controller in questione ma non ce n'erano. Quindi per risolvere il problema ho pensato bene di utilizzare uno strumento molto potente contenuto in git: il comando bisect.
In pratica tramite esso è possibile effettuare una bisecazione fra coppie di snapshot di codice caratterizzate dal contenere o meno il baco che si cerca di risolvere: se il baco è stato introdotto in un particolare commit è possibile trovarlo raffinando ad ogni passo l'intervallo da bisecare.
Per prima cosa si parte definendo la coppia di commit da cui iniziare: uno
buono, rappresentato dalla revisione indicata con la tag v2.0, ed uno
cattivo che è l'attuale HEAD:
$ git bisect start
$ git bisect bad
$ git bisect good v2.0
A questo punto git effettuerà il checkout di un commit che si trova a metà fra i due appena indicati; l'utente effettua i propri tests e deciderà se il commit è buono
$ git bisect good
oppure no
$ git bisect bad
fino a che non rimane un solo commit per cui il nostro strumento di versioning ci avvisa che è questo il commit che ha introdotto il baco
4cc6e967075e75c5f9dca8798609c7f333d3e0f2 is the first bad commit
commit 4cc6e967075e75c5f9dca8798609c7f333d3e0f2
Author: Gianluca <gianluca@MBP-DFUN.local>
Date: Mon Apr 18 10:40:47 2011 +0200
Add footer which is missing in some views.
Because of this we have to reparent some table within a view and add manually
the property tableView.
:040000 040000 f2daebc6bf95879c91e7bc4dc24ad4baaa1dee74 625993b0272a9e0f18d98bd12ffdf1190b3d1213 M LumBancoProva
:040000 040000 eb48902995d470bace32c37837a7ac4ab61b0670 417f22a4e0121c7ce6947b764add79397932728d M LumLib
In pratica il problema riscontrato era dovuto ad un reparenting della
UITableView dentro ad una UIView andando a non inviare il messaggio -
(void)setEditing:(BOOL)editing animated:(BOOL)animate alla table view ma alla
view.
Non immagino come avrei potuto risolvere diversamente questa spiacevole regressione. Come ultima considerazione c'è da tenere conto che in caso di processo automatizzato è possibile indicare a bisect uno script da utilizzare per marcare i vari commit come buoni o cattivi rendendo il processo immediato.
git: recuperare uno stash droppato per sbaglio
Nel mio normale workflow uso spesso git stash assieme alla suite di tests eventualmente presenti nel progetto a cui lavoro, per assicurarmi che ad un commit non manchino parti funzionali utili; la procedura è la seguente (facendo finta che sia un progetto Django)
$ git commit
$ git stash
$ python manage.py test
$ git stash pop
Una volta però mi è successo di dare un drop di troppo andando a perdere lo stash appena salvato
$ git stash drop
Dropped refs/stash@{0} (2b1f538fc094df2a8391c7462ae6586995f3fef4)
fortuna vuola che fino a che non si esegue un git gc anche gli elementi non direttamente referenziati rimangano nel database degli oggetti del repository permettendone l'eventuale utilizzo; eseguendo
$ git stash apply 2b1f538fc094df2a8391c7462ae6586995f3fef4
è possibile recuperare lo stash perduto.
Debug una chiamata SOAP con netcat
Può succedere di dover debuggare una chiamata ad un servizio web esterno (nel mio caso una chiamata SOAP) effettuata attraverso un wrapper PHP; può succedere che la chiamata fallisca e il messaggio risulti veramente criptico e si necessiti di dover avere accesso all'XML effettivamente scambiato fra lo script e il server esterno, ma come fare?
Basta utilizzare ncat come
proxy in locale con l'accortezza
di usarne un'altra istanza per ottenere effettivamente il flusso in input ed
output delle chiamate: se da un terminale si esegue
$ ncat --sh-exec "tee /tmp/stdin.txt | ncat localhost 8080 | tee /tmp/stdout.txt" -l 8888 -vvv
si crea una socket bindato alla porta 8888 che reindirizza sempre in locale
alla porta 8080, scrivendo però su file stdin.txt e stdout.txt
rispettivamente le richieste in entrata e quelle in uscita; sulla porta 8080
mettiamo in ascolto ncat in modalità proxy
$ ncat -l 8080 --proxy-type http -vvvv
A questo punto impostando lo script ad usare come proxy localhost alla
porta 8888 posso ottenere il flusso di dati in entrata ed in uscita.
Update: Mi accorgo solo ora che è possibile usare una variabile trace
con la quale poter farsi restituire l'XML inviato con le librerie SOAP PHP. Poco male,
qualcosa l'ho imparato lo stesso ;-).
GDB e SIGTRAP
Mi sono ritrovato a debuggare al lavoro una applicazione IPhone che crashava
senza però lasciarmi con la console di gdb in modo da ottenere un
backtrace.
Lavorandoci sopra sono arrivato alla conclusione che l'applicazione riceveva un
segnale di SIGTRAP, segnale che viene usato dai debugger stessi per i loro
breakpoints: nel caso specifico ,una libreria interna del SDK, "emetteva"
questo segnale confondendo così il debugger che non si fermava in maniera
corretta.
Per correggere questo problema basta indicare a gdb di "inoltrare il
segnale" all'applicazione in maniera tale da in effetti ottenere poi un
terminale del debugger funzionante; per fare ciò basta impostare un breakpoint
ad inizio dell'applicazione (per andare sul sicuro magari nel main()) e poi
dare il comando
(gdb) handle SIGTRAP pass
(gdb) c
e per magia vi ritrovete appunto con la linea di comando di gdb al prossimo crash.
Per saperne di più al riguardo di come gestire i segnali con gdb questo è il suo relativo help
(gdb) help handle
Specify how to handle a signal.
Args are signals and actions to apply to those signals.
Symbolic signals (e.g. SIGSEGV) are recommended but numeric signals
from 1-15 are allowed for compatibility with old versions of GDB.
Numeric ranges may be specified with the form LOW-HIGH (e.g. 1-5).
The special arg "all" is recognized to mean all signals except those
used by the debugger, typically SIGTRAP and SIGINT.
Recognized actions include "stop", "nostop", "print", "noprint",
"pass", "nopass", "ignore", or "noignore".
Stop means reenter debugger if this signal happens (implies print).
Print means print a message if this signal happens.
Pass means let program see this signal; otherwise program doesn't know.
Ignore is a synonym for nopass and noignore is a synonym for pass.
Pass and Stop may be combined.
Il formato JPEG
La teoria dell'informazione è in buona parte una formalizzazione della capacità di trasmettere informazione ed un sinonimo della capacità di compressione di un certo stream di simboli; proprio per questo le sue tecniche sono diventate molto importanti nelle tecnologie informatiche ed in alcuni degli ambiti propri dell'informatica hanno permesso la diffusione di "cultura" prima impensabili.
Proprio in merito ad un formato di compressione voglio parlare in questo post,
il formato conosciuto come JPEG. La particolarità di questo formato è che
unisce molte delle caratteristiche dei formati di compressione più comuni, in
particolare la codifica di huffman, la trasformata discreta del coseno
ed una variante del run length encoding. Tutto questo per permettere di
avere una immagine che perde sì qualità rispetto all'immagine originale, ma non
in modo tale da perdere contenuto di informazione ottica.
Ma prima di entrare nei dettagli della specifica un minimo di storia, perché
anche l'informatica è fatta da persone: per prima cosa il nome JPEG
proviene dal J oint P hotographic E xperts G roup, un comitato
che si proponeva il compito di creare uno standard per la diffusione di
immagini tramite internet (questo all'inizio degli anni '90). La sua origine
accademica tuttavia è riconducibile al 1970 all'incirca, quando due ricercatori
cercavano una immagine da inserire all'interno di un loro paper ed essendo
stanchi delle solite immagini decisero di scannerizzare una porzione della pin
up nel paginone centrale di playboy, l'immagine che diventerà poi famosa con il
nome di Lenna
 The first lady of internet
The first lady of internet
Tornando alla implementazione, la specifica del comitato ISO è definita qui ed è riassumibile nei seguenti steps
- Trasformare l'immagine dallo spazio
RGBaYCbCr - downsampling
- Suddividere le immagini in blocchi 8x8 effettuando il padding dove serve
- trasformata discreta del coseno su ognuno dei blocchi
- quantizzazione
- entropy coding e zero length encoding
Analizziamo uno step alla volta.
RGB -> YCbCr
Bene o male chiunque abbia avuto a che fare con la grafica conosce lo spazio
dei colori definito come RGB che sta per red, green e blu, ma
non è il solo sistema possibile
per identificare un colore.
L'identificazione nasce dalla natura fisiologica della visione: l'occhio umano ha una visione tricromatica (caso raro tra i vertebrati che passano da essere tetracromatici a dicromatici)
Ma già dalle lezioni di educazione artistica delle medie sappiamo che esistono almeno due tipologie di schemi di colori, lo schema additivo e lo schema sottrattivo: il primo si basa sulla proprietà additiva della luce in cui si hanno tre colori primari che mescolati generano tramite "addizione" tutti i colori possibili, mentre il secondo è usato nella tipografia (schema CMYK) ed è detto sottrattivo in quanto i colori primari sottraggono ciascuno un colore primario dalla luce riflessa (Il ciano sottrae il rosso, il magenta sottrae il verde ed infine il giallo sottrae il blu). A meno che non vi interessi stampare, lo schema di colori è quello additivo.
Tra gli schemi di colori interessanti nella grafica digitale è il YUV che permette di separare la componente di luminanza (quanto è bianca o nera l'immagine) dalle componenti cromatiche; la scelta di questo schema di colori è importante in quato l'occhio umano è molto più sensibile alla luminanza che alle componenti cromatiche oltre che affermatosi storicamente tramite le trasmissioni televisive in bianco e nero.
Downsampling
Siccome l'occhio umano è più sensibile alla luminanza rispetto alla componente
cromatica, è possibile risparmiare bandwidth diminuendo opportunamente la
quantità di informazione cromatica rispetto all'unità di informazione Y;
questa procedura è standard nel campo delle comunicazioni se teniamo conto che
la trasmissione analogica della programmazione televisiva avviene trasmettendo
la crominanza (UV) con una banda dimezzata rispetto alla luminanza.
Nel caso specifico del JPEG il downsampling può essere effettuato sia
verticalmente che orizzontalmente per ogni componente; nelle specifiche viene
indicato che per ricostruire il rapporto di una dimensione dei blocchi dopo il
downsampling si deve dividere il fattore di sampling di quella componente
rispetto al fattore di sampling più elevato fra le varie componenti, cioé in
pratica se si ha un fattore di sampling per le tre componenti nei rapporti
2:1:1 significa che la prima componente è quella senza subsampling e che le
rimanenti hanno un un numero di pixel dimezzati rispetto a questa.
Di solito il fattore di sampling standard per una immagine JPEG è 2x2, 1x1, 1x1.
MCU
A questo punto, nel caso in cui ci si ritrova con più di una componente si effettua una suddivisione dell'immagine in blocchi 8x8 e un raggruppamento di questi blocchi in delle cosiddette minimal coded unit (MCU, per le immagini ad una sola componente la MCU è il singolo blocco). L'ordinamento delle sequenze dei blocchi è dato dal subsampling: all'interno della MCU i blocchi sono ordinati top-bottom, left-right ed il medesimo ordinamento è seguito dalle MCU all'interno dell'immagine. Per capirci, lo schema usato è il seguente
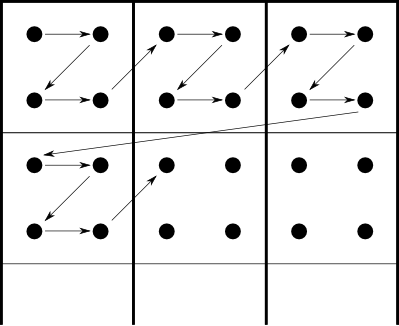
Nella figura i pallini rappresentano i valori della componente, i quadrati interni rappresentano la MCU e le freccie l'ordinamento seguito per l'encoding/decoding
In caso l'immagine non sia di dimensioni tali da avere un numero intero di MCU si completano quelli mancanti aggiungendo valori nulli.
DCT
Si arriva adesso alla parte fondamentale: si effettua la trasformata discreta del coseno che trasforma i 64 valori nel singolo blocco in altri 64 valori che rappresentano i valori delle frequenze corrispondenti del blocco originale; i valori nel punto corrispondente all'angolo alto a sinistra corrisponde alla frequenza più bassa (cioé la frequenza nulla). Le formule per questo passaggio sono $$ S_{u,v} = {1\over 4} C_u C_v \sum_{x=0}^7 \sum_{y=0}^7 S_{xy}\cos{(2x + 1)u\pi\over16}\cos{(2y + 1)v\pi\over16} $$
Quantization
Per diminuire la quantità di informazione necessaria per immagazzinare i valori delle componenti, si definisce una matrice di quantizzazione la quale permette di definire il valore finale dell'entrata del blocco tramite $$ Sq_{ij} = \hbox{round} \left(S_{ij}\over Q_{ij}\right) $$ Questo passaggio è quello che in pratica determina la qualità dell'immagine (se la matrice è composta da elementi tutti uguali all'unità allora la qualità è 100 e l'immagine non perde rispetto all'originale).
Encoding
Il passaggio di encoding vero e proprio avviene a questo punto: per ogni blocco
si effettua un ordinamento delle varie componenti detto a zig zag, in modo da
avere i valori derivanti dalle alte frequenze e quindi meno importanti per la
ricostruzione del valore originale in fondo alla sequenza. Quindi si
differenzia la componente a frequenza \(u, v=0\), detta DC, dalle
rimanenti, dette AC.

La componente DC viene encodata come coppia di valori \((cc, m)\) dove
\(cc\) sta ad indicare il numero di bits che bisogna usare per encodare il
valore di DC in \(m\) usando una rappresentazione in complemento a 2.
Però prima di fare questo il suo valore viene posto uguale alla differenza fra
esso ed il coefficiente precedente (se è il primo blocco allora si prende il
valore reale), questo procedimento è detto differential DC encoding.
Ogni componente AC invece viene encodata come tripletta \((cc,zl,m)\)
dove il primo valore indica quanti bits sono necessari per encodare in una
rappresentazione in complemento a 2 il valore di AC dentro \(m\), mentre
\(zl\) indica quanti valori nulli di AC precedono questo. Esiste una
sequenza particolare che indica l'end of block (EOB) che informa del
fatto che le rimanenti componenti sono nulle e che il blocco è quindi finito;
questo corrisponde a \(cc=0\) e \(zl=0\).
C'è da notare che per i valori di DC si usano 8 bits per rappresentare
\(cc\), mentre ne servono 4 per l'omonimo in AC e altri 4 per \(zl\);
quindi si ha che \(cc\) per DC e la coppia \((cc,zl)\) per AC
vengono memorizzati tramite la codifica di Huffman utilizzando una tabella
separata.
Implementazione
Ovviamente non ritengo di avere espresso esaurientemente l'argomento in quanto
nelle specifiche si parla di quattro tipologie di JPEG di cui non ho
accennato, ma per un approccio iniziale penso che la spiegazione può ritenersi
sufficiente, del resto esiste la specifica che può essere studiata anche da
soli.
Prima di fare un esempio voglio solo indicare come effettivamente è organizzato
un file di immagini in questo formato; prima di tutto le sezioni sono
delimitate inizialmente da un marker composto da due byte, il primo è
sempre 0xff mentre il secondo identifica opportunamente il marker. Grosso
modo quelli più importanti sono i seguenti
| Marker | Output | Significato |
|---|---|---|
| 0xffd8 | Start of file | primo byte del file |
| 0xffc0 | Start of frame | identifica un blocco dell'immagine da decodare a cui seguiranno tabella di Huffman, di Quantizazione etc... qui sono contenute le informazioni riguardanti la dimensione, il numero di colori (1 oppure 3). |
| 0xffc4 | huffman table | ce ne sono 2 o 4 a seconda del numero di colori siccome se ne usa una per la componente AC ed una per la componente DC per luminanza e crominanza separatamente. |
| 0xffdb | Quantization table | unica per tutte le componenti |
| 0xffda | Scan data | contiene zig-zag entropy coded data |
| 0xffd9 | End of JPEG | ultimo byte del file |
ESEMPIO
Dopo i dettagli implementativi, ecco un piccolo esempio con un semplice file di dimensioni 8x8 di colore rosso:
$ hexdump -C <( convert -size 8x8 -quality 100 xc:red jpg:- )
00000000 ff d8 ff e0 00 10 4a 46 49 46 00 01 01 01 00 48 |......JFIF.....H|
00000010 00 48 00 00 ff db 00 43 00 01 01 01 01 01 01 01 |.H.....C........|
00000020 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 |................|
*
00000050 01 01 01 01 01 01 01 01 01 ff db 00 43 01 01 01 |............C...|
00000060 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 |................|
*
00000090 01 01 01 01 01 01 01 01 01 01 01 01 01 01 ff c0 |................|
000000a0 00 11 08 00 08 00 08 03 01 11 00 02 11 01 03 11 |................|
000000b0 01 ff c4 00 14 00 01 00 00 00 00 00 00 00 00 00 |................|
000000c0 00 00 00 00 00 00 09 ff c4 00 14 10 01 00 00 00 |................|
000000d0 00 00 00 00 00 00 00 00 00 00 00 00 00 ff c4 00 |................|
000000e0 15 01 01 01 00 00 00 00 00 00 00 00 00 00 00 00 |................|
000000f0 00 00 09 0a ff c4 00 14 11 01 00 00 00 00 00 00 |................|
00000100 00 00 00 00 00 00 00 00 00 00 ff da 00 0c 03 01 |................|
00000110 00 02 11 03 11 00 3f 00 17 c5 3a fe 1f ff d9 |......?...:....|
0000011f
Linkografia
- Differenza fra RGB e CYMK
- RGB-vs-CMYK
- Specifiche JPEG
- The Scientist and Engineer's Guide to Digital Signal Processing
- Data compression explained
- Bandwidth Versus Video Resolution
- Mia implementazione in C di un parser JPEG
- Digital media primer for geek
- FOURCC.org - your source for video codec and pixel format information.
git: come impostare un diff custom per file binari
git fondamentalmente è nato per gestire il versioning di codice sorgente
(cioé per farla breve file di testo) quindi qualunque file di tipo diverso, che
lui riconosce come binario, non ha disponibilità di tutte le funzionalità
possibili ed in particolare del diffing. Se per esempio abbiamo sotto
versioning un immagine chiamata logo.png, l'unico messaggio che otteniamo è
$ git diff
diff --git a/logo.png b/logo.png
index f9e1a4e..2ed156d 100644
Binary files a/logo.png and b/logo.png differ
Nel caso preso ad esempio è possibile customizzare facilmente il diffing impostando il file .gitattributes segnalando che i file con estensione png devono essere visualizzati in tal caso usando un comando esterno; poniamo di voler usare exiftool
*.png diff=exif
possiamo impostare questo programma tramite git config
$ git config diff.exif.textconv exiftool
Esistono tuttavia dei casi più complicati: per esempio mi sono ritrovato ad
usare Xmind per gestire l'organizzazione di un
progetto e la cosa fastidiosa era il non sapere esattamente quali parti erano
state modificate fra una sessione di lavoro e l'altra al primo colpo d'occhio;
per ovviare a questo ho dovuto prima capire le caratteristiche del formato in
cui vengono salvati i dati con questo programma: in pratica i file .xmind
sono archivi zip che contengono alcuni files
$ unzip prova.xmind
Archive: prova.xmind
inflating: meta.xml
inflating: content.xml
inflating: styles.xml
inflating: Thumbnails/thumbnail.jpg
inflating: META-INF/manifest.xml
I files sono file XML, purtroppo non indentati, risultando così molto
scomodi da leggere; a questo si può ovviare utilizzando xsltproc ed un file
XSLT così strutturato
$ cat indent.xml
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" indent="yes"/>
<xsl:strip-space elements="*"/>
<xsl:template match="/">
<xsl:copy-of select="."/>
</xsl:template>
</xsl:stylesheet>
nella seguente maniera
$ xsltproc --novalid indent.xml content.xml
ottenendo in file XML che è più facile da visualizzare. Unendo questi
piccoli tricks possiamo dare vita al seguente script (chiamiamolo
dexmind.sh)
#!/bin/bash
if [ $# -lt 7 ]
then
exit 1
fi
OLDCWD=$PWD
TMP=$(mktemp -d)
cd ${TMP}
mkdir old
mkdir new
OLDFILE="$2"
NEWFILE="$1"
unzip "${OLDFILE}" -d old/
unzip "${OLDCWD}"/"${NEWFILE}" -d new/
diff -Nur <( xsltproc --novalid indent.xml old/content.xml ) \
<( xsltproc --novalid indent.xml new/content.xml )
rm -fr "${TMP}"
Quindi se le varie versioni di xmind vengono salvate tramite git basta impostare nella seguente maniera il repository
$ cat .gitattributes
*.xmind diff=xmind
$ git config diff.xmind.command dexmind.sh
per ottenere una visualizzazione "comoda" utilizzando un semplice git diff.
--- /dev/fd/63 2010-06-01 12:27:58.002961037 +0200
+++ /dev/fd/62 2010-06-01 12:27:58.002961037 +0200
@@ -275,7 +275,7 @@
<topic id="3goion232e7fvk0osuq5fbpnj0" timestamp="1274806579104
<title>data DDT arrivo</title>
</topic>
- <topic id="3364831d74ngrnrcgal21nfsmg" timestamp="1274806583479
+ <topic id="3364831d74ngrnrcgal21nfsmg" style-id="075vnn7k0jvogp
<title>giorni giacenza</title>
accidentally by zero
Facendo ripetizioni ad un ragazzo del politecnico mi sono ritrovato a dover risolvere un esercizio relativo ai numeri complessi, cioé trovare il valore di \(\ln (-i)^8\) ; il tutto pare abbastanza straightforward (tenendo conto che \(z=a+ib=\rho e^{i\theta}\)).
$$ \eqalign{ \ln\left(-i\right)^8 &= 8\ln \left(-i\right)\cr &= 8\left(\ln 1 -i{\pi\over2} \right)\cr &= -4i \pi \cr } $$ il problema arriva se uno tenta di risolverlo direttamente calcolando il valore di \((-i)^8\)
$$ \eqalign{ \ln\left(-i\right)^8 &= \ln\left[(-i)^{2\cdot4}\right]\cr &= \ln\left[(-1)^4\right]\cr &= \ln 1 \cr &= 0 \cr } $$ Come è possibile avere due risultati differenti? semplicemente perché nell'analisi complessa le funzioni non si comportano "bene" come l'analisi matematica su \(R\) ma alcune di esse possono essere polidrome (cioé allo stesso dominio possono coincidere immagini attraverso la funzione diverse). Nel caso del logaritmo questo è abbastanza ovvio se consideriamo che un numero (in questo caso complesso scritto in notazione polare) rimane invariato se moltiplicato per 1
$$ z\cdot 1 = z\cdot e^{i2\pi}$$
ma non il suo logaritmo
$$\ln z = \ln z + i\,2\pi$$
Questo significa appunto che la funzione logaritmo è una funzione a molti valori la cui immagine risiede su una superficie di Riemann ad infiniti fogli, quindi i due risultati sono stati calcolati semplicemente su due fogli diversi. Quindi alla fine, entrambi i valori sono esatti, semplicemente calcolati su fogli diversi.
Patent Absurdity
Piccolo documentario in lingua inglese riguardante un caso particolare di brevetto software
Sul sito è possibile scaricarlo in alta qualità tramite torrent, ovviamente in formato Theora.
i comandi di git: for-each-ref
Il mio strumento di versioning preferito è proprio git se non lo aveste
capito; la bellezza di questo tool sta proprio nella sua versatilità e nella
suo essere toolbox, una scatola degli attrezzi pronta all'uso per il versioning
dei propri progetti software. Con questo post inizio una carrellata sui comandi
di git, magari più ignoti che potrebbero servirvi nel vostro lavoro di
sviluppo.
Il comando che andremo a vedere si chiama for-each-ref e già il nome può
darci indicazioni cosa si può ottenere da esso: una lista di tutto le referenze
del nostro repository, selezionando eventualmente un pattern particolare (solo
le tags per esempio).
Non c'è molto da spiegare se non vedere l'help presente
$ git for-each-ref -h
usage: git for-each-ref [options] [<pattern>]
-s, --shell quote placeholders suitably for shells
-p, --perl quote placeholders suitably for perl
--python quote placeholders suitably for python
--tcl quote placeholders suitably for tcl
--count <n> show only <n> matched refs
--format <format> format to use for the output
--sort <key> field name to sort on
ed un possibile script di esempio che esegua, in un repository contenente un
progetto Django, gli unit tests per ognuno dei branch e ci stampi alla fine il
codice di uscita del test e la referenza a cui si riferisce, ordinandole per
risultato (attenzione che alla fine ci si ritrova con una detached HEAD)
git for-each-ref refs/heads | while read hash type ref
do
git checkout $hash 2>/dev/null
python manage.py test >/dev/null 2>&1
echo $ref $?
done | sort -k2,2
Un output può essere il seguente
refs/heads/backup 0
refs/heads/fix-comma 0
refs/heads/lighttpd 0
refs/heads/make-tex-from-post 0
refs/heads/archeology 1
refs/heads/archives 1
refs/heads/better-500-page 1
refs/heads/export 2
Utile se si vuole tenere sott'occhio quali branch hanno bisogno di lavoro.
Un altro modo di utilizzare questo comando è di trovare a quale branch corrisponde un dato commit: dentro uno script bash definite la sequente funzione
find_ref () {
git for-each-ref refs/heads | while read sha1 type ref;
do
if [ "$sha1" == "$1" ]
then
echo $ref
fi
done
}
a questo punto potete passare lo sha1 a 40 cifre a questa funzione e trovare il path completo all'interno del namespace delle referenze a cui corrisponde quella. Unico problema è che se ci sono più branch che puntano allo stesso commit non c'è modo di disambiguarli.
Deployment di un progetto Django
Siccome Django è un framework web e siccome esso mette a disposizione degli strumenti per il test locale, in un corretto modello di sviluppo e testing la parte in cui i cambiamenti vengono resi noti al mondo esterno in un server reale, rappresentano un passaggio importante e delicato; i passaggi devono essere automatizzati in maniera tale da evitare di dimenticarli o compierli in maniera errata (sopratutto se il sito in questione non è usato direttamente dallo sviluppatore, il quale non può accorgersi di eventuali problemi anche piccoli che possono presentarsi).
Possiamo dividere le buone pratiche per un corretto deploy (TM) principalmente in due categorie:
- accorgimenti da prendere quando si scrive il codice.
- strategia per il deploy/upgrade sul server.
Uno dei problemi più sentiti, che potenzialmente può essere molto lungo da risolvere e, sopratutto, non prevedibili consiste nella gestione delle dipendenze a cui è soggetta la tua web application, sopratutto nel caso in cui essa conviva nello stesso shared hosting con altre che richiedono versioni diverse delle librerie: per risolvere questo scenario sono possibili due vie (nel caso in cui voi usiate un version manager software, ma voi lo usate vero;-))
- salvare le dipendenze nel vostro SCM.
- usare una sandbox per le vostre librerie (per esempio virtualenv).
Io propendo per la seconda opzione siccome permette di lasciare più snello il progetto, evitando di portarsi dietro MB di librerie (spesso in forma binaria) che poi risulterebbe veramente difficile poter aggiornare se non sporcando inevitabilmente la storia del vostro repository (nel caso in cui voi usiate un version manager software, ma voi lo usate vero;-)). Ovviamente per lo stesso motivo sarebbe inutile tenere sotto versioning la sandbox anche nell'ottica di una automatizzazione: mica volete uno script che vi registri anche l'hosting in automatico? certi passaggi vanno fatti bene e automatizzati ma, è questo il punto importante, a parte e non assieme al deploy vero e proprio, magari con tempistiche proprie e coerenti con il loro scopo.
Impostazioni iniziali
Sempre nell'ottica della customizzabilità delle impostazioni della vostra web
application, è pratica giusta e buona inserire nel file settings.py le
impostazioni comuni con i settaggi più restrittivi ed usare un file
local_settings.py da importare con le specifiche impostazioni per la
specifica installazione. Infatti una delle cose più fastidiose all'inizio è
dover cambiare tutte le variabili che impostano i percorsi, in alcuni casi
assoluti, che sicuramente cambieranno già solo nei momenti di debug in computer
usati per lo sviluppo; un esempio su tutti è la variabile TEMPLATE_DIRS.
Quindi primo passo è creare una variabile che contenga il path del progetto nel nostro filesystem usando la keyword __file__
PROJECT_ROOT_PATH = os.path.abspath(os.path.dirname(__file__))
modifichiamo MEDIA_ROOT, MEDIA_URL e ADMIN_MEDIA_PREFIX
MEDIA_ROOT = PROJECT_ROOT_PATH + '/media/'
MEDIA_URL = '/media/'
ADMIN_MEDIA_PREFIX = '/admin_media/'
Cancelliamo dal file globale la SECRET_KEY e
creiamone una nuova nelle impostazioni locali per vari motivi:
-
se si usa un SCM (per di più condiviso) la secret key può essere visibile al pubblico e quindi portare a problemi di sicurezza (non sono sicuro ma dovrebbe avere a che fare con le autenticazioni), del resto la frase
# Make this unique, and don't share it with anybodypresente sopra la sua definizione insettings.pydovrebbe essere chiara. -
deve essere diversa per ogni installazione, quindi impostata a mano nel
local_settings.py.
Rendere ROOT_URLCONF locale, cioé togliendogli il prefisso con il nome del progetto
ROOT_URLCONF = 'urls'
Indicare la directory dei templates globale
TEMPLATE_DIRS = (
PROJECT_ROOT_PATH + 'templates/'
)
Infine al termine del file inserire questa porzione di codice che legge da un file locale le impostazioni, in maniera tale da avere per ogni sito la propria configurazione ottimale
# local_settings.py can be used to override environment-specific settings
# like database and email that differ between development and production.
try:
from local_settings import *
except ImportError:
print 'Do you have a \'local_settings\'?'
TEMPLATE_DEBUG = DEBUG
MANAGERS = ADMINS
Le ultime due righe permettono di impostare quei valori in base al contenuto di local_settings.py.
Static Files
Uno dei piccoli problemi che si incontra nel deploy è quello dei file statici che in un server di produzione non devono essere serviti da django; per la parte propria di django il seguente pezzo di codice rende i file serviti dal nostro amato framework sono nel caso in cui si stia eseguendo il debug
# urls.py
if settings.DEBUG:
urlpatterns += patterns('',
(r'^media/(?P<path>.*)$', 'django.views.static.serve',
{'document_root': settings.MEDIA_ROOT,
'show_indexes': True}),
)
Può essere utile anche un file .htaccess nel caso utilizziate un server Apache con mod_rewrite abilitato
RewriteEngine On
RewriteBase /
RewriteRule ^(media/.*)$ - [L]
RewriteRule ^(admin_media/.*)$ - [L]
RewriteRule ^(dispatch\.fcgi/.*)$ - [L]
RewriteRule ^(.*)$ dispatch.fcgi/$1 [L]
Per admin_media è presumibile fare un link simbolico (che si spera il web
server permetta) alla directory django/contrib/admin/media/.
Mentre si scrive il codice
Personalmente uso un preciso schema per tenere a mente e verificare quali passaggi mancano nel codice
-
scrivere un
FIXMEoTODOa seconda dei casi, nelle righe immediatamente vicine a quelle porzioni di codice che necessitano delle migliorie. Per ritrovarle è sufficiente usare il buon vecchogrep. -
ricordarsi che se si eseguono dei test che riguardano
django.contrib.authbisogna includere anchedjango.contrib.adminaltrimenti vengono a mancare dei templates utili e i tests falliscono.
Dipendenze
Utilizzando pip è possibile ottenere un modo automatizzato di
verificare/installare le dovute dipendenze tramite un semplice comando ed in
più ottenere tramite un semplice file di testo l'elenco delle stesse.
Però prima di pensare in un progetto specifico alle dipendenze ritengo più utile sviluppare le funzionalità di base ottenendo così di non perdere tempo inutilmente a cambiare di continuo il file delle dipendenze.
Quando ci si ritrova ad un punto “di arrivo” (magari nel deploy su un server
esterno) è possibile usare pip per ottenere un elenco delle dipendenze che
attualmente sono presenti localmente.
$ pip freeze
Spesso ci si ritrova a dover lavorare su diversi progetti che devono
condividere la stessa macchina pur non condividendo le stesse librerie (oppure
condividendole ma non le loro versioni utili). Si necessita quindi di avere
degli ambienti puliti e isolati per ogni progetto: a questo serve
virtualenv.
$ cd path/to/project
$ virtualenv --no-site-packages env
New python executable in env/bin/python2.6
Also creating executable in env/bin/python
Installing setuptools............done.
$ source env/bin/activate
(env) $
Come si può notare il prompt è cambiato e questo indica che si sta usando esclusivamente il python contenuto dentro la directory env/.
Se si usa debian come distribuzione è possibile che si abbia una versione di pip un po' obsoleta (tipo 0.3 contro una versione 0.6 disponibile sul sito) quindi è possibile usare il virtualenv appena impostato e scaricare la nuova versione
(env) $ easy_install pip
e di seguito installare da un file di dipendenze creato precedentemente
(env) $ pip install -r dependencies.txt # --ignore-installed
N.B: attenzione che la variabile PYTHONPATH non punti da qualche parte esterna al virtualenv in quanto lo scavalcherebbe.
Ancora prima di eseguire un test live tramite l'utilizzo di un browser, nel caso si stia utilizzando WSGI/Fcgi come interfaccia per eseguire Django sul server potete provare a lanciare da linea di comando l'eseguibile stesso
$ PATH_INFO=/path/to/page ./dispatch.fcgi
ed osservare se effettivamente risultano o no errori (/path/to/page è il
percorso della pagina che volete testare il quale, per le specifiche di queste
gateway interfaces, deve essere passato attraverso variabili d'ambiente, cioé
PATH_INFO in questo caso).
Dati iniziali
Una volta caricato il codice sul server è necessario prima di tutto controllare che il codice funzioni, lanciando gli unit test (perché voi scrivete gli appositi tests per ogni vostra unità si codice, vero?); in caso contrario significa che i passaggi effettuati precedentemente sono stati fallaci.
Confermato che il codice funzioni sul vostro server, escludendo problemi di
dipendenze (o al massimo trovandone di nuove :-P) possiamo passare al rendere
operativo il sito; come da manuale, lanciare un syncdb dovrebbe bastare per
risolvere tutti i vostri problemi se avete avuto l'accortezza di inserire
all'interno di una directory fixtures una fixture appunto, denominata
initial_data relativa a dati fissi del vostro sito (come per esempio delle
flatpages)
$ python manage.py syncdb
Ma quali sono i dati che in generale sono necessari includere nel progetto?
- Se poi la vostra applicazione/sito fornisce la possibilità di loggarsi, sarà d'uopo creare almeno il superuser durante il syncdb; eventualmente si vorrà creare un utente con permessi limitati (buona pratica di sicurezza, perché voi ci tenete alla sicurezza, vero?).
$ python manage.py shell
>>> from django.contrib.auth.models import User
>>> help(User.objects.create_user)
Help on method create_user in module django.contrib.auth.models:
create_user(self, username, email, password=None) method of django.contrib.auth.models.UserManager instance
Creates and saves a User with the given username, e-mail and password.
>>> User.objects.create_user('gp', 'gp@no.spam.org', password='password')
-
dati relativi alla applicazione
django.contrib.sitesche tengano conto dell'effettivo dominio utilizzato dal hosting. -
come detto appena sopra ci possono essere delle pagine che non verranno editate frequentemente e magari di carattere generale nel sito le quali conviene tenere sotto forma di flatpages (basti pensare alla pagina about). Una nota aggiuntiva a questo: il formato migliore per salvare questo tipo di dato sotto forma di fixture è lo YAML, il quale permette di avere del codice molto più pulito e leggibile rispetto all'XML e JSON, formati standard di solito usati in Django. Questo semplicemente perché permette di poter preservare newline. Leggibilità prima di tutto.
Backup
Non vi crederete mica che una volta messo su il sito voi abbiate finito? esiste il problema dell'eventuale backup che è sempre meglio fare, perché per quanto siate intelligenti e fortunati l'imprevedibile è sempre in agguato e perdere magari anni di lavoro non è mai bello. Tralasciamo quale sia la migliore via per fare un backup, limitandoci a pensare al come e non al dove (non che il dove non sia già impegnativo); come sempre ci sono due vie
-
fare il dump del database nel suo formato proprio (le sfilze di
CREATE TABLE,INSERTper capirci) -
fare il dump attraverso il comando dumpdata proprio di Django.
La seconda via è molto più comoda nel caso in cui ci si ritrovi a dover ricaricare i dati in un progetto simile, tuttavia se non si ha la possibilità di utilizzare django-admin si ha un cumulo di dati non direttamente importabili. Al contrario è possibile ricaricare in qualunque caso i dati dumpati con il database nel suo formato nativo.